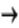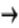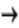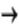Overview
The following section provides a brief introduction to the purpose and structure of the EViews model object, and introduces terminology that will be used throughout the rest of the chapter.
A model consists of a set of equations that describe the relationships between a set of variables.
The variables in a model can be divided into two categories: those determined inside the model, which we refer to as the endogenous variables, and those determined outside the model, which we refer to as the exogenous variables. A third category of variables, the add factors, are a special case of exogenous variables.
In its most general form, a model can be written in mathematical notation as:
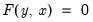 | (52.1) |
where
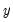
is the vector of endogenous variables,
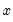
is the vector of exogenous variables, and
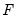
is a vector of real-valued functions
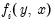
. For the model to have a unique solution, there should typically be as many equations as there are endogenous variables.
In EViews, each equation in the model must have a unique endogenous variable assigned to it. That is, each equation in the model must be able to be written in the form:
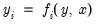 | (52.2) |
where
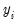
is the endogenous variable assigned to equation
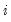
. EViews has the ability to
normalize equations involving simple transformations of the endogenous variable, rewriting them automatically into explicit form when necessary. Any variable that is not assigned as the endogenous variable for any equation is considered exogenous to the model.
Equations in an EViews model can either be inline or linked. An inline equation contains the specification for the equation as text within the model. A linked equation is one that brings its specification into the model from an external EViews object such as a single or multiple equation estimation object, or even another model. Linking allows you to couple a model more closely with the estimation procedure underlying the equations, or with another model on which it depends. For example, a model for industry supply and demand might link to another model and to estimated equations:
|
| link to macro model object for forecasts of total consumption |
| link to equation object containing industry supply equation |
| link to equation object containing industry demand equation |
| inline identity: supply = demand |
Equations can also be divided into stochastic equations and identities. Roughly speaking, an identity is an equation that we would expect to hold exactly when applied to real world data, while a stochastic equation is one that we would expect to hold only with random error. Stochastic equations typically result from statistical estimation procedures while identities are drawn from accounting relationships between the variables.
The most important operation performed on a model is to solve the model. By solving the model, we mean that for a given set of values of the exogenous variables, X, we will try to find a set of values for the endogenous variables, Y, so that the equations in the model are satisfied within some numerical tolerance. Often, we will be interested in solving the model over a sequence of periods, in which case, for a simple model, we will iterate through the periods one by one. If the equations of the model contain future endogenous variables, we may require a more complicated procedure to solve for the entire set of periods simultaneously.
In EViews, when solving a model, we must first associate data with each variable in the model by binding each of the model variables to a series in the workfile. We then solve the model for each observation in the selected sample and place the results in the corresponding series.
When binding the variables of the model to specific series in the workfile, EViews will often modify the name of the variable to generate the name of the series. Typically, this will involve adding an extension of a few characters to the end of the name. For example, an endogenous variable in the model may be called “Y”, but when EViews solves the model, it may assign the result into an observation of a series in the workfile called “Y_0”. We refer to this mapping of names as aliasing. Aliasing is an important feature of an EViews model, as it allows the variables in the model to be mapped into different sets of workfile series, without having to alter the equations of the model.
When a model is solved, aliasing is typically applied to the endogenous variables so that historical data is not overwritten. Furthermore, for models which contain lagged endogenous variables, aliasing allows us to bind the lagged variables to either the actual historical data, which we refer to as a static forecast, or to the values solved for in previous periods, which we refer to as a dynamic forecast. In both cases, the lagged endogenous variables are effectively treated as exogenous variables in the model when solving the model for a single period.
Aliasing is also frequently applied to exogenous variables when using model scenarios. Model scenarios allow you to investigate how the predictions of your model vary under different assumptions concerning the path of exogenous variables or add factors. In a scenario, you can change the path of an exogenous variable by overriding the variable. When a variable is overridden, the values for that variable will be fetched from a workfile series specific to that scenario. The name of the series is formed by adding a suffix associated with the scenario to the variable name. This same suffix is also used when storing the solutions of the model for the scenario. By using scenarios it is easy to compare the outcomes predicted by your model under a variety of different assumptions without having to edit the structure of your model.
The following table gives a typical example of how model aliasing might map variable names in a model into series names in the workfile:
| | |
endogenous Y |  | Y | historical data |
| | Y_0 | baseline solution |
| | Y_1 | scenario 1 |
exogenous X | | X | historical data followed by baseline forecast |
| | X_1 | overridden forecast for scenario 1 |
Earlier, we mentioned a third category of variables called add factors. An add factor is a special type of exogenous variable that is used to shift the results of a stochastic equation to provide a better fit to historical data or to fine-tune the forecasting results of the model. While there is nothing that you can do with an add factor that could not be done using exogenous variables, EViews provides a separate interface for add factors to facilitate a number of common tasks.