Variance Ratio Test
The question of whether asset prices are predictable has long been the subject of considerable interest. One popular approach to answering this question, the Lo and MacKinlay (1988, 1989) overlapping variance ratio test, examines the predictability of time series data by comparing variances of differences of the data (returns) calculated over different intervals. If we assume the data follow a random walk, the variance of a
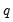
-period difference should be
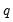
times the variance of the one-period difference. Evaluating the empirical evidence for or against this restriction is the basis of the variance ratio test.
EViews allows you to perform the Lo and MacKinlay variance ratio test for homoskedastic and heteroskedastic random walks, using the asymptotic normal distribution (Lo and MacKinlay, 1988) or wild bootstrap (Kim, 2006) to evaluate statistical significance. In addition, you may compute the rank, rank-score, or sign-based forms of the test (Wright, 2000), with bootstrap evaluation of significance. In addition, EViews offers Wald and multiple comparison variance ratio tests (Richardson and Smith, 1991; Chow and Denning, 1993), so you may perform joint tests of the variance ratio restriction for several intervals.
Performing Variance Ratio Tests in EViews
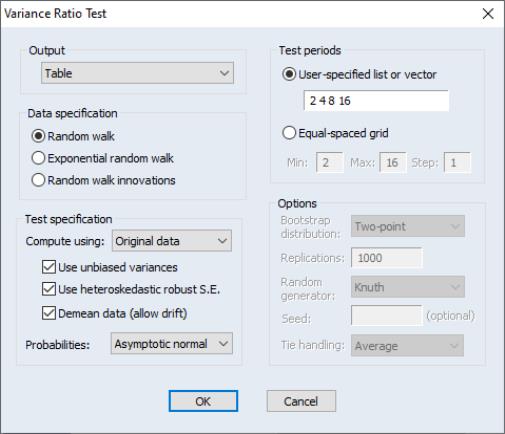
First, open the series which contains the data which you wish to test and click on Note that EViews allows you to perform the test using the differences, log differences, or original data in your series as the random walk innovations.
The dropdown determines whether you wish to see your test output in or form. (As we discuss below, the choices differ slightly in a panel workfile.)
The section describes the properties of the data in the series. By default, EViews assumes you wish to test whether the data in the series follow a , so that variances are computed for differences of the data. Alternately, you may assume that the data follow an so that the innovations are obtained by taking log differences, or that the series contains the themselves.
The section describes the method used to compute your test. By default, EViews computes the basic Lo and MacKinlay variance ratio statistic assuming heteroskedastic increments to the random walk. The default calculations also allow for a non-zero innovation mean and bias correct the variance estimates.
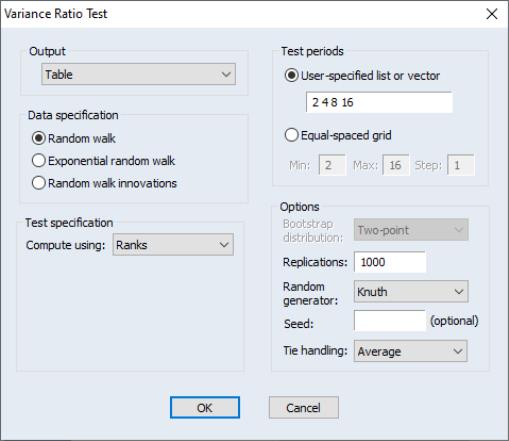
The dropdown, which defaults to , instructs EViews to use the original Lo and MacKinlay test statistic based on the innovations obtained from the original data. You may instead use the dropdown to instruct EViews to perform the variance ratio test using , (van der Waerden scores), or of the data.
For the Lo and MacKinlay test statistic, the three checkboxes directly beneath the dropdown allow you to choose whether to bias-correct the variance estimates, to construct the test using the heteroskedasticity robust test standard error, and to allow for non-zero means in the innovations. The dropdown may be used to select between computing the test probabilities using the default results (Lo and MacKinlay 1988), or using the (Kim 2006). If you choose to perform a wild bootstrap, the portion on the lower right of the dialog will prompt you to choose a bootstrap error distribution (, , ), number of replications, random number generator, and to specify an optional random number generator seed.
For variance ratio test computed using , (van der Waerden scores), or of the data, the probabilities will be computed by permutation bootstrapping using the settings specified under . For the ranks and rank scores tests, there is an additional option for the method of assigning ranks in the presence of tied data.
Lastly, the section identifies the intervals whose variances you wish to compare to the variance of the one-period innovations. You may specify a single period or more than one period; if there is more than one period, EViews will perform one ore more joint tests of the variance ratio restrictions for the specified periods.
There are two ways to specify the periods to test. First, you may provide a user-specified list of values or name of a vector containing the values. The default settings, depicted above, are to compute the test for periods “2 4 8 16.” Alternately, you may click on the radio, and enter a minimum, maximum, and step.
If you are performing your test on a series in a panel workfile, the options differ slightly. If you wish to produce output in tabular form, you can choose to compute individual variance ratio tests for each cross-section and form a Fisher Combined test (), or you can choose to stack the cross-sections into a single series and perform the test on the stacked panel (). Note that the stacked panel method assumes that all means and variances are the same across all cross-sections; the only adjustment for the panel structure is in data handling that insures that lags never cross the seams between cross-sections. There are two graphical counterparts to the table choices: , which produces a graph for each cross-section, and , which produces a graph of the results for the stacked analysis.
An Example
In our example, we employ the time series data on nominal exchange rates used by Wright (2000) to illustrate his modified variance ratio tests (“Wright.WF1”). The data in the first page (WRIGHT) of the workfile provide the relative-to-U.S. exchange rates for the Canadian dollar, French franc, German mark, Japanese yen, and the British pound for the 1,139 weeks from August 1974 through May 1996. Of interest is whether the exchange rate returns, as measured by the log differences of the rates, are i.i.d. or martingale difference, or alternately, whether the exchange rates themselves follow an exponential random walk.
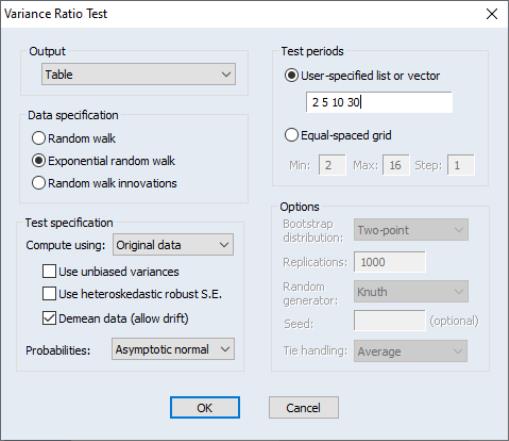
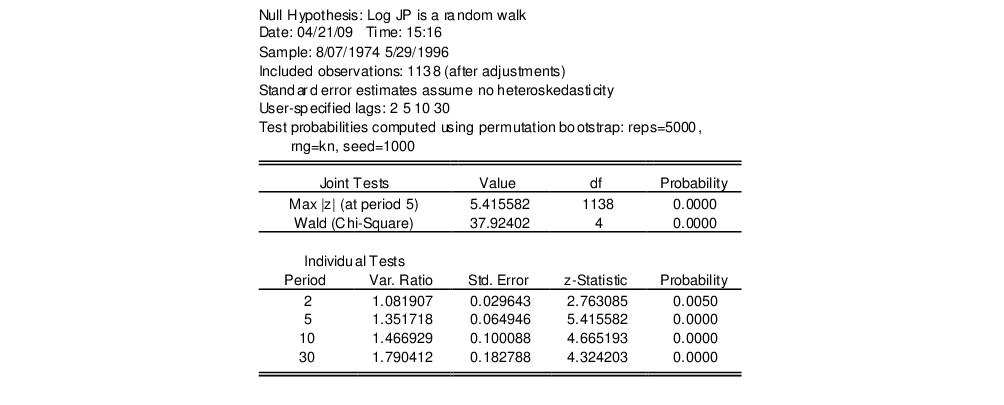
We begin by performing tests on the Japanese yen. Open the JP series, then select ... to display the dialog. We will make a few changes to the default settings to match Wright’s calculations. First, select in the section to tell EViews that you wish to work with the log returns. Next, uncheck the and checkboxes to perform the i.i.d. version of the Lo-MacKinlay test with no bias correction. Lastly, change the user-specified test periods to “2 5 10 30” to match the test periods examined by Wright. Click on to compute and display the results.
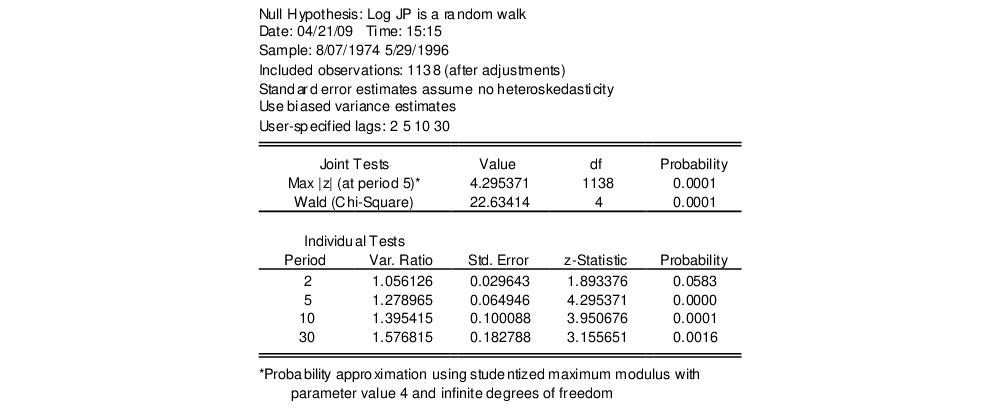
The top portion of the output shows the test settings and basic test results.
Since we have specified more than one test period, there are two sets of test results. The “Joint Tests” are the tests of the joint null hypothesis for all periods, while the “Individual Tests” are the variance ratio tests applied to individual periods. Here, the Chow-Denning maximum
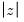
statistic of 4.295 is associated with the period 5 individual test. The approximate
p-value of 0.0001 is obtained using the studentized maximum modulus with infinite degrees of freedom so that we strongly reject the null of a random walk. The results are quite similar for the Wald test statistic for the joint hypotheses. The individual statistics generally reject the null hypothesis, though the period 2 variance ratio statistic
p-value is slightly greater than 0.05.
The bottom portion of the output shows the intermediate results for the variance ratio test calculations, including the estimated mean, individual variances, and number of observations used in each calculation.
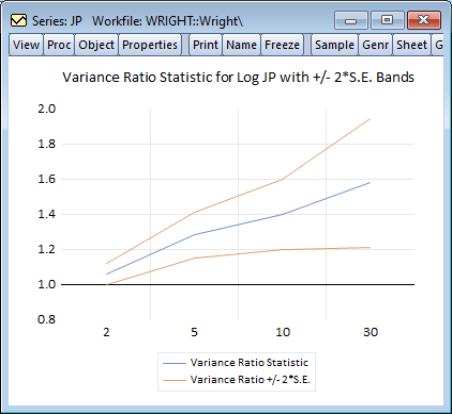
Alternately, we may display a graph of the test statistics using the same settings. Simply click again on , change the dropdown from to , then fill out the dialog as before and click on :
EViews displays a graph of the variance ratio statistics and plus or minus two asymptotic standard error bands, along with a horizontal reference line at 1 representing the null hypothesis. Here, we see a graphical representation of the fact that with the exception of the test against period 2, the null reference line lies outside the bands.
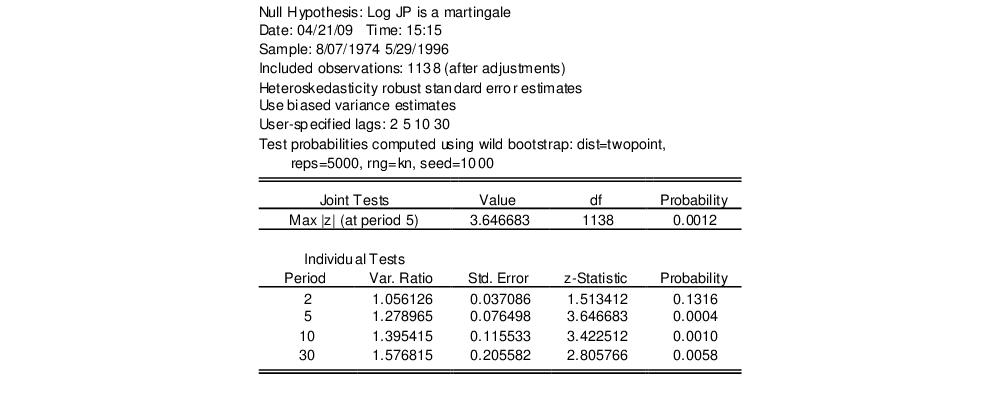
Next, we repeat the previous analysis but allow for heteroskedasticity in the data and use bootstrapping to evaluate the statistical significance. Fill out the dialog as before, but enable the checkbox and use the dropdown to select (with the two-point distribution, 5000 replications, the Knuth generator, and a seed for the random number generator of 1000 specified in the section). The top portion of the results is depicted here:
Note that the Wald test is no longer displayed since the test methodology is not consistent with the use of heteroskedastic robust standard errors in the individual tests. The p-values for the individual variance ratio tests, which are all generated using the wild bootstrap, are generally consistent with the previous results, albeit with probabilities that are slightly higher than before. The individual period 2 test, which was borderline (in)significant in the homoskedastic test, is no longer significant at conventional levels. The Chow-Denning joint test statistic of 3.647 has a bootstrap p-value of 0.0012 and strongly rejects the null hypothesis that the log of JP is a martingale.
Lastly, we perform Wright’s rank variance ratio test with ties replaced by the average of the tied ranks. The test probabilities for this test are computed using the permutation bootstrap, whose settings we select to match those for the previous bootstrap:
The standard errors employed in forming the individual
z-statistics (and those displayed in the corresponding graph view) are obtained from the asymptotic normal results. The probabilities for the individual
z-statistics and the joint max
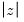
and Wald statistics, which all strongly reject the null hypothesis, are obtained from the permutation bootstrap.
The preceding analysis may be extended to tests that jointly consider all five exchange rates in a panel setting. The second page (WRIGHT_STK) of the “Wright.WF1” workfile contains the panel dataset of the relative-to-U.S. exchange rates described above (Canada, Germany, France, Japan, U.K.). Click on the WRIGHT_STK tab to make the second page active, double click on the EXCHANGE series to open the stacked exchange rates series, then select
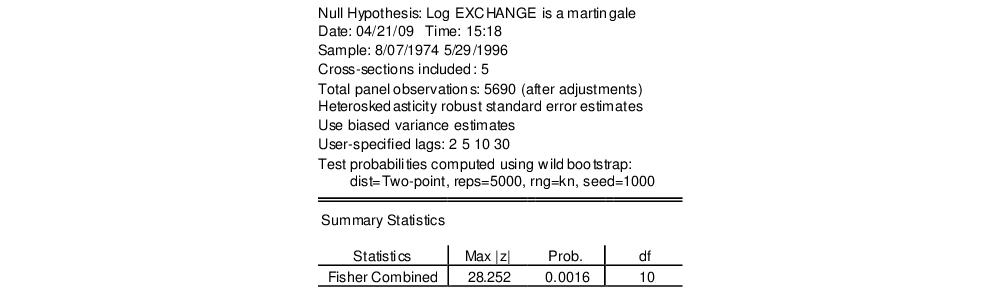
We will redo the heterogeneous Lo and MacKinlay test example from above using the panel data series. Select in the dropdown then fill out the remainder of the dialog as before, then click on . The output, which takes a moment to generate since we are performing 5000 bootstrap replications for each cross-section, consists of two distinct parts. The top portion of the output:
shows the test settings and provides the joint Fisher combined test statistic which, in this case, strongly rejects the joint null hypothesis that all of the cross-sections are martingales.
The bottom portion of the output:
depicts the max
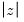
statistics for the individual cross-sections, along with corresponding wild bootstrap probabilities. Note that four of the five individual test statistics do not reject the joint hypothesis at conventional levels. It would therefore appear that the Japanese yen result is the driving force behind the Fisher combined test rejection.
Technical Details
Suppose we have the time series
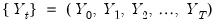
satisfying
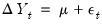 | (42.108) |
where
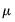
is an arbitrary drift parameter. The key properties of a random walk that we would like to test are
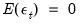
for all
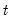
and
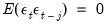
for any positive
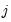
.
The Basic Test Statistic
Lo and MacKinlay (1988) formulate two test statistics for the random walk properties that are applicable under different sets of null hypothesis assumptions about
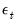
:
First, Lo and MacKinlay make the strong assumption that the
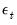
are i.i.d. Gaussian with variance
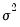
(though the normality assumption is not strictly necessary). Lo and MacKinlay term this the homoskedastic random walk hypothesis, though others refer to this as the
i.i.d. null.
Alternately, Lo and MacKinlay outline a heteroskedastic random walk hypothesis where they weaken the
i.i.d. assumption and allow for fairly general forms of conditional heteroskedasticity and dependence. This hypothesis is sometimes termed the martingale null, since it offers a set of sufficient (but not necessary), conditions for
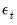
to be a martingale difference sequence (
m.d.s.).
We may define estimators for the mean of first difference and the scaled variance of the
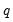
‑th difference:
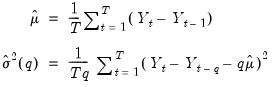 | (42.109) |
and the corresponding variance ratio
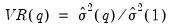
. The variance estimators may be adjusted for bias, as suggested by Lo and MacKinlay, by replacing
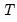
in
Equation (42.109) with
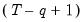
in the no-drift case, or with
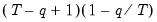
in the drift case.
Lo and MacKinlay show that the variance ratio z-statistic:
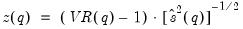 | (42.110) |
is asymptotically
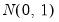
for appropriate choice of estimator
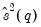
.
Under the i.i.d. hypothesis we have the estimator,
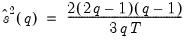 | (42.111) |
while under the m.d.s. assumption we may use the kernel estimator,
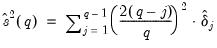 | (42.112) |
where
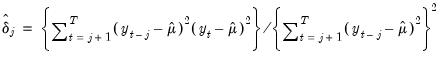 | (42.113) |
Joint Variance Ratio Tests
Since the variance ratio restriction holds for every difference
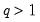
, it is common to evaluate the statistic at several selected values of
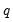
.
To control the size of the joint test, Chow and Denning (1993) propose a (conservative) test statistic that examines the maximum absolute value of a set of multiple variance ratio statistics. The
p-value for the Chow-Denning statistic using
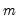
variance ratio statistics is bounded from above by the probability for the Studentized Maximum Modulus (SMM) distribution with parameter
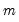
and
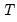
degrees-of-freedom. Following Chow and Denning, we approximate this bound using the asymptotic
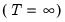
SMM distribution.
An second approach is available for variance ratio tests of the
i.i.d. null. Under this set of assumptions, we may form the joint covariance matrix of the variance ratio test statistics as in Richardson and Smith (1991), and compute the standard Wald statistic for the joint hypothesis that all
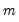
variance ratio statistics equal 1. Under the null, the Wald statistic is asymptotic Chi-square with
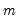
degrees-of-freedom.
For a detailed discussion of these tests, see Fong, Koh, and Ouliaris (1997).
Wild Bootstrap
Kim (2006) offers a wild bootstrap approach to improving the small sample properties of variance ratio tests. The approach involves computing the individual (Lo and MacKinlay) and joint (Chow and Denning, Wald) variance ratio test statistics on samples of
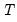
observations formed by weighting the original data by mean 0 and variance 1 random variables, and using the results to form bootstrap distributions of the test statistics. The bootstrap
p-values are computed directly from the fraction of replications falling outside the bounds defined by the estimated statistic.
EViews offers three distributions for constructing wild bootstrap weights: the two-point, the Rademacher, and the normal. Kim’s simulations indicate that the test results are generally insensitive to the choice of wild bootstrap distribution.
Rank and Rank Score Tests
Wright (2000) proposes modifying the usual variance ratio tests using standardized ranks of the increments,
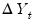
. Letting
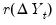
be the rank of the
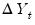
among all
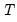
values, we define the standardized rank
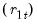
and van der Waerden rank scores
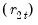
:
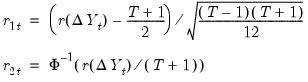 | (42.114) |
In cases where there are tied ranks, the denominator in
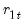
may be modified slightly to account for the tie handling.
The Wright variance ratio test statistics are obtained by computing the Lo and MacKinlay homoskedastic test statistic using the ranks or rank scores in place of the original data. Under the i.i.d. null hypothesis, the exact sampling distribution of the statistics may be approximated using a permutation bootstrap.
Sign Test
Wright also proposes a modification of the homoskedastic Lo and MacKinlay statistic in which each
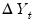
is replaced by its sign. This statistic is valid under the
m.d.s. null hypothesis, and under the assumption that
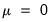
, the exact sampling distribution may also be approximated using a permutation bootstrap. (EViews does not allow for non-zero means when performing the sign test since allowing
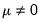
introduces a nuisance parameter into the sampling distribution.)
Panel Statistics
EViews offers two approaches to variance ratio testing in panel settings.
First, under the assumption that cross-sections are independent, with cross-section heterogeneity of the processes, we may compute separate joint variance ratio tests for each cross-section, then combine the
p-values from cross-section results using the Fisher approach as in Maddala and Wu (1999). If we define
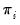
to be a
p-value from the
i-th cross-section, then under the hypothesis that the null hypothesis holds for all
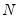
cross-sections,
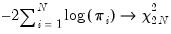 | (42.115) |
as
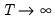
.
Alternately, if we assume homogeneity across all cross-sections, we may stack the panel observations and compute the variance ratio test for the stacked data. In this approach, the only adjustment for the panel nature of the stacked data is in ensuring that lag calculations do not span cross-section boundaries.