Setting up a Pool Workfile
Your goal in setting up a pool workfile is to obtain a workfile containing individual series for ordinary variables, sets of appropriately named series for the cross-section specific data, and pool objects containing the related sets of identifiers. The workfile should have frequency and range matching the time series dimension of your pooled data.
There are two basic approaches to setting up such a workfile. The direct approach involves first creating an empty workfile with the desired structure, and then importing data into individual series using either standard or pool specific import methods. The indirect approach involves first creating a stacked representation of the data in EViews, and then using EViews built-in reshaping tools to set up a pooled workfile.
Direct Setup
The direct approach to setting up your pool workfile involves three distinct steps: first creating a workfile with the desired time series structure; next, creating one or more pool objects containing the desired cross-section identifiers; and lastly, using pool object tools to import data into individual series in the workfile.
Creating the Workfile and Pool Object
The first step in the direct setup is to create an ordinary EViews workfile structured to match the time series dimension of your data. The range of your workfile should represent the earliest and latest dates or observations you wish to consider for any of the cross-section units.
Simply select to bring up the dialog which you will use to describe the structure of your workfile. For additional detail, see
“Creating a Workfile by Describing its Structure” .
For example, to create a pool workfile that has annual data ranging from 1950 to 1992, simply select in the dropdown menu, and enter “1950” as the and “1992” as the .
Next, you should create one or more pool objects containing cross-section identifiers and group definitions as described in
“The Pool Object”.
Importing Pooled Data
Lastly, you should use one of the various methods for importing data into series in the workfile. Before considering the various approaches, we require an understanding the various representations of pooled time series, cross-section data that you may encounter.
Bear in mind that in a pooled setting, a given observation on a variable may be indexed along three dimensions: the variable, the cross-section, and the time period. For example, you may be interested in the value of GDP, for the U.K., in 1989.
Despite the fact that there are three dimensions of interest, you will eventually find yourself working with a two-dimensional representation of your pooled data. There is obviously no unique way to organize three-dimensional data in two-dimensions, but several formats are commonly employed.
Unstacked Data
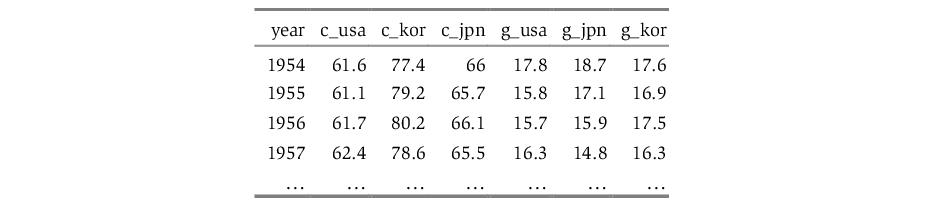
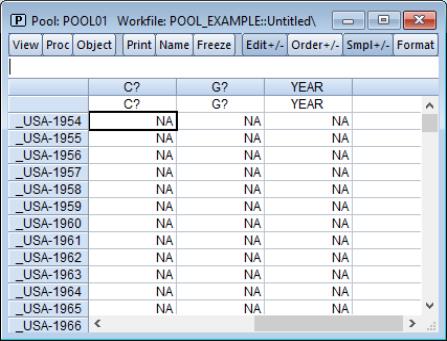
In this form, observations on a given variable for a given cross-section are grouped together, but are separated from observations for other variables and other cross sections. For example, suppose the top of our Excel data file contains the following:
Here, the base name “C” represents consumption, while “G” represents government expenditure. Each country has its own separately identified column for consumption, and its own column for government expenditure.
EViews pooled workfiles are structured to work naturally with data that are unstacked, since the sets of cross-section specific series in the pool workfile correspond directly to the multiple columns of unstacked source data. You may read unstacked data directly into EViews using the standard workfile creation procedures described in
“Creating a Workfile by Reading from a Foreign Data Source” . Each cross-section specific variable should be read as an individual series, with the names of the resulting series follow the pool naming conventions given in your pool object. Ordinary series may be imported in the usual fashion with no additional complications.
In this example, we should use the standard EViews tools to read separate series for each column. We create the individual series “YEAR”, “C_USA”, “C_KOR”, “C_JPN”, “G_USA”, “G_JPN”, and “G_KOR”.
Stacked Data
Pooled data can also be arranged in stacked form, where all of the data for a variable are grouped together in a single column.
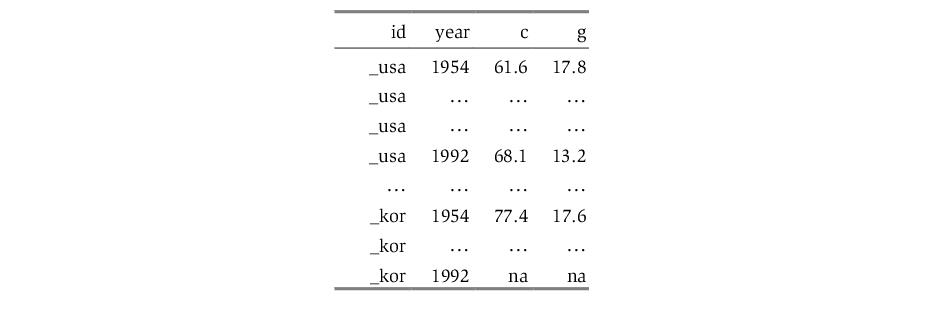
In the most common form, the data for different cross-sections are stacked on top of one another, with all of the sequentially dated observations for a given cross-section grouped together. We may say that these data are stacked by cross-section:
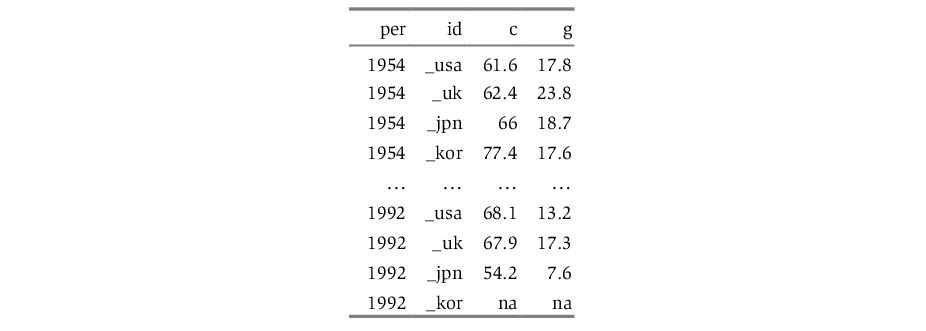
Alternatively, we may have data that are stacked by date, with all of the observations of a given period grouped together:
Each column again represents a single variable, but within each column, all of the cross-sections for a given year are grouped together. If data are stacked by year, you should make certain that the ordering of the cross-sectional identifiers within a year is consistent across years.
There are to primary approaches to importing data into your pool series: you may read the data in stacked form then use EViews tools to restructure the data in pool form, or you may directly read or copy the data into a stacked representation of the pooled series.
Indirect Setup (Restructuring) of Stacked Data
The easiest approach to reading stacked pool data is to create an EViews workfile containing the data in stacked form, and then use the built-in workfile reshaping tools to create a pool workfile with the desired structure and data. (Alternately, you can perform the first step and simply work with the data in stacked form: see
“Working with Panel Data” for details.)
The first step in the indirect setup of a pool workfile is to create a workfile containing the contents of your stacked data file. You may manually create the workfile and import the stacked series data, or you may use EViews tools for opening foreign source data directly into a new workfile (
“Creating a Workfile by Reading from a Foreign Data Source” ).
Once you have your stacked data in an EViews workfile, you may use the workfile reshaping tools to unstack the data into a pool workfile page. In addition to unstacking the data into multiple series, EViews will create a pool object containing identifiers obtained from patterns in the series names. See
“Reshaping a Workfile” for a general discussion of reshaping, and
“Unstacking a Workfile” for a more specific discussion of the unstack procedure.
The indirect method is generally easier to use than the direct approach and has the advantage of not requiring that the stacked data be balanced. It has the disadvantage of using more computer memory since EViews must have two copies of the source data in memory at the same time.
Direct Import of Stacked Data
An alternative approach is to enter or read the data directly into the workfile using a pool object. You may enter or copy-and-paste data from the source into and a stacked representation of your data, or you may use the pool object to describe how to read the stacked data into the unstacked workfile.
To enter data or copy-and-paste, you use the pool object to create a stacked representation of the data in EViews:
• First, specify which time series observations will be included in your stacked spreadsheet by setting the workfile sample.
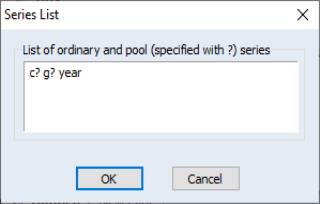
• Next, open the pool, then select EViews will prompt you for a list of series. You can enter ordinary series names or pool series names. If the series exist, then EViews will display the data in the series. If the series do not exist, then EViews will create the series or group of series, using the cross-section identifiers if you specify a pool series.
• EViews will open the stacked spreadsheet view of the pool series. If desired, click on the button to toggle between stacking by cross-section and stacking by date.
• Click to turn on edit mode in the spreadsheet window, and enter your data, or cut-and-paste from another application.
For example, if we have a pool object that contains the identifiers “_USA”, “_UK”, “_JPN”, and “_KOR”, we can instruct EViews to create the series C_USA, C_UK, C_JPN, C_KOR, and G_USA, G_UK, G_JPN, G_KOR, and YEAR simply by entering the pool series names “C?”, “G?” and the ordinary series name “YEAR”, and pressing .
EViews will open a stacked spreadsheet view of the series in your list. Here we see the series stacked by cross-section, with the pool or ordinary series names in the column header, and the cross-section/date identifiers labeling each row. Note that since YEAR is an ordinary series, its values are repeated for each cross-section in the stacked spreadsheet.
If desired, click on to toggle between stacking methods to match the organization of the data to be imported. Click on to turn on edit mode, and enter or cut-and-paste into the window.
Alternatively, you can import stacked data from a file using import tools built into the pool object. While the data in the file may be stacked either by cross-section or by period, EViews does require that the stacked data are “balanced,” and that the cross-sections ordering in the file matches the cross-sectional identifiers in the pool. By “balanced,” we mean that if the data are stacked by cross-section, each cross-section should contain exactly the same number of periods—if the data are stacked by date, each date should have exactly the same number of cross-sectional observations arranged in the same order.
We emphasize that only the representation of the data in the import file needs to be balanced; the underlying data need not be balanced. Notably, if you have missing values for some observations, you should make certain that there are lines in the file representing the missing values. In the two examples above, the underlying data are not balanced, since information is not available for Korea in 1992. The data in the file have been balanced by including an observation for the missing data.
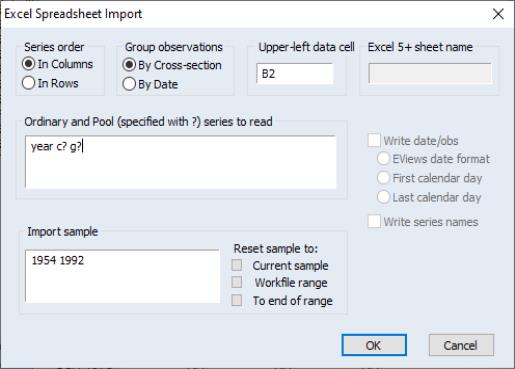
To import stacked pool data from a file, first open the pool object, then select It is important that you use the import procedure associated with the pool object, located on the pool proc menu, and not the standard file import procedure.
Select your input file in the usual fashion. If you select a spreadsheet file, EViews will open a spreadsheet import dialog prompting you for additional input.
First, indicate whether the pool series are in rows or in columns, and whether the data are stacked by cross-section, or stacked by date.
Next, in the pool series edit box, enter the names of the series you wish to import. This list may contain any combination of ordinary series names and pool series names.
Lastly, fill in the sample information, starting cell location, and optionally, the sheet name.
When you specify your series using pool series names, EViews will, if necessary, create and name the corresponding set of pool series using the list of cross-section identifiers in the pool object. If you list an ordinary series name, EViews will, if needed, create a single series to hold the data.
EViews will read the contents of your file into the specified pool variables using the sample information. When reading into pool series, the first set of observations in the file will be placed in the individual series corresponding to the first cross-section (if reading data that is grouped by cross-section), or the first sample observation of each series in the set of cross-sectional series (if reading data that is grouped by date), and so forth.
If you read data into an ordinary series, EViews will continually assign values into the corresponding observation of the single series, so that upon completion of the import procedure, the series will contain the last set of values read from the file.
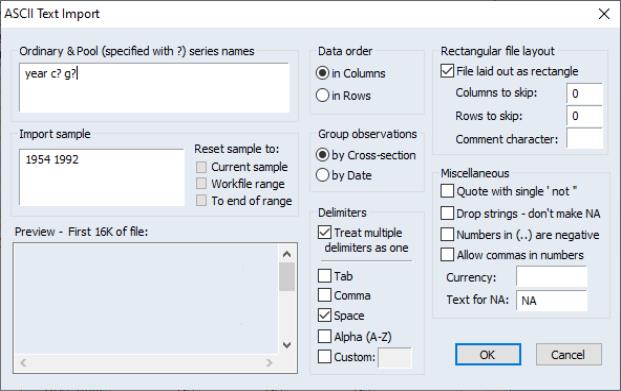
The basic technique for importing stacked data from ASCII text files is analogous, but the corresponding dialog contains many additional options to handle the complexity of text files.
For a discussion of the text specific settings in the dialog, see
“References” .
Alternately, you may read in the data into a panel workfile, and then use