Groups
EViews provides specialized tools for working with groups of series that are held in the form of a group object. In
“Importing Data”, we used groups to import data from spreadsheets into existing workfiles. Briefly, a group is a collection of one or more series identifiers or expressions. Note that a group does not contain the data in the individual series, only references to the data in the series.
To create a group, select and fill in the dialog with names of series and auto-series. Or you may select from the workfile toolbar and fill out the dialog. Alternatively, type the command group in the command window, followed by a name to be given to the group and then the series and auto-series names:
group macrolist gdp invest cons
creates the group MACROLIST containing the series GDP, INVEST and CONS. Similarly,
group altlist log(gdp) d(invest) cons/price
creates the group ALTLIST containing the log of the series GDP, the first difference of the series INVEST, and the CONS series divided by the PRICE series.
There are a few features of groups that are worth keeping in mind:
• A group is simply a list of series identifiers. It is not a copy of the data in the series. Thus, if you change the data for one of the series in the group, you will see the changes reflected in the group.
• If you delete a series from the workfile, the series identifier will be maintained in all groups. If you view the group spreadsheet, you will see a phantom series containing NA values. If you subsequently create or import the series, the series values will be restored in all groups.
• Renaming a series changes the reference in every group containing the series, so that the newly named series will still be a member of each group.
• There are many routines in EViews where you can use a group name in place of a list of series. If you wish, for example, to use X1, X2, and X3 as right-hand side variables in a regression, you can instead create a group containing the series, and use the group in the regression.
We describe groups in greater detail in
“Groups”.
Accessing Individual Series in a Group
Groups, like other EViews objects, contain their own views and procedures. For now, note that you can access the individual elements of a named group as individual series.
To refer the
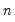
-th series in the group, simply append “(
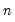
)” to the group name. For example, consider the MACROLIST group, defined above. The expression MACROLIST(1) may be used to refer to GDP and MACROLIST(2) to refer to INVEST.
You can work with MACROLIST(1) as though it were any other series in EViews. You can display the series by clicking on the button on the toolbar and entering MACROLIST(1). You can include GDP in another group directly or indirectly. A group which contains:
macrolist(1) macrolist(2)
will be identical to a group containing
gdp invest
We can also use the individual group members as part of expressions in generating new series:
series realgdp = macrolist(1)/price
series y = 2*log(macrolist(3))
or in modifying the original series:
series macrolist(2) = macrolist(2)/price
Note that in this latter example the series keyword is required, despite the fact that the INVEST series already exists. This is true whenever you access a series as a member of a group.
Other tools allow you to retrieve the number of series in a group using the @count group data member:
scalar numgroup = macrolist.@count
To retrieve the names of each of the series, you may use the group data member
@seriesname. These tools are described in greater detail in
“Group”.
Group Row Functions
EViews allows you to generate a series based upon the rows, or observations, in a group. The most simple of these is the @columns function which simply returns a series where every observation is equal to the number of series in a group. This function provides exactly the same information as the @count data member of a group. Thus the expression:
series numgroup = @columns(macrolist)
produces the same result as:
series numgroup = macrolist.@count
There are also functions that will calculate the mean of a group’s rows (@rmean), their standard deviation (@rstdev) and variance (@rvar).
The @rvalcount function can be used to find how many times a specific value occurs within the rows of a group. For example:
series numvals = @valcount(macrolist,5)
will create a series where each row of that series will be the count of how many of the series within the MACROLIST group contain the value “5” for that particular row. Note that the value argument for this function can be a scalar or a series.
A full list of the group row functions can be found in
“By-Row Statistics”.
Creating a Group By Expanding a Series
The @expand function allows you to create a group of dummy variables by expanding out one or more series into individual categories. For example, if the series UNION contains values equal to either “union”, “non-union”, then using:
group g1 @expand(union)
will create a group, G1, with two series, the first series containing 1 where-ever union is equal to “union” and zero elsewhere, the second series containing 1 where-ever union is equal to “non-union” and zero elsewhere.
@expand may also be used on more than one series to give the cross-interaction of different series. Thus if you have a second series called MARRIED that contains either “married” or “single” then entering:
group g2 @expand(union,married)
will create a group, G2, with four series, the first containing 1 where-ever UNION is equal to “union” and MARRIED is equal to “married”, the second series containing a 1 where-ever UNION is equal to “union” and MARRIED is equal to “single”, and so on.
The @expand function can be used as part of a mathematical expression, so that a command of:
group g3 2*@expand(union)
will create a group where the first series contains a 2 where-ever UNION is equal to “union”. Further,
group g4 log(income)*@expand(married)
creates a group where the first series is equal to the values of the log of INCOME where-ever MARRIED is equal to “married” and so on.
The of the most useful applications of the @expand function is when specifying an equation object, since it can be used to automatically create dummy variables.
An Illustration
Auto-series and group processing provides you with a powerful set of tools for working with series data. As we saw above, auto-series provide you with dynamic updating of expressions. If we use the auto-series expression:
log(y)
the result will be automatically updated whenever the contents of the series Y changes.
A potential drawback of using auto-series is that expressions may be quite lengthy. For example, the two expressions:
log(gdp)/price + d(invest) * (cons + invest)
12345.6789 * 3.14159 / cons^2 + dlog(gdp)
are not suited to use as auto-series if they are to be used repeatedly in other expressions.
You can employ group access to make this style of working with data practical. First, create groups containing the expressions:
group g1 log(gdp)/price+d(invest)*(cons+invest)
group g2 12345.6789*3.14159/cons^2+dlog(gdp)
If there are spaces in the expression, the entire contents should be enclosed in parentheses.
You can now refer to the auto-series as G1(1) and G2(1). You can go even further by combining the two auto-series into a single group:
group myseries g1(1) g2(1)
and then referring to the series as MYSERIES(1) and MYSERIES(2). If you wish to skip the intermediate step of defining the subgroups G1 and G2, make certain that there are no spaces in the subexpression or that it is enclosed in parentheses. For example, the two expressions in the group ALTSERIES,
group altseries (log(gdp)/price) 3.141*cons/price
may be referred to as ALTSERIES(1) and ALTSERIES(2).