Variable Selection Estimation in EViews
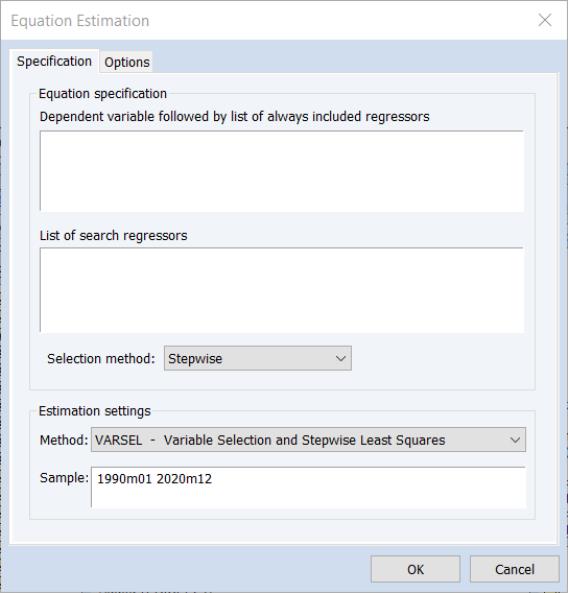
To perform a variable selection procedure (VARSEL) in EViews select or press from the toolbar of an existing equation. From the dialog choose. EViews will display the following dialog:
The page allows you to provide the basic VARSEL regression specification. In the upper edit field you should first specify the dependent variable followed by the always included variables you wish to use in the final regression. Note that the VARSEL equation must be specified by list.
You should enter a list of variables to be used as the set of potentially included variables in the second edit field.
The dropdown box can be used to specify the type of selection procedure will be used to determine the final model. By default, EViews will estimate the variable selection using the method. To change the basic method, change the method dropdown menu; the dropdown allows you to choose between: , , , , and selection.
Next, you may use the Options tab to more finely tune the selection method. The options available will depend on the selection method chosen, and are described below.
Estimation Options
When you select one of the variable selection methods, the tab of the dialog will change to display the relevant settings.
Uni-directional and Stepwise Options
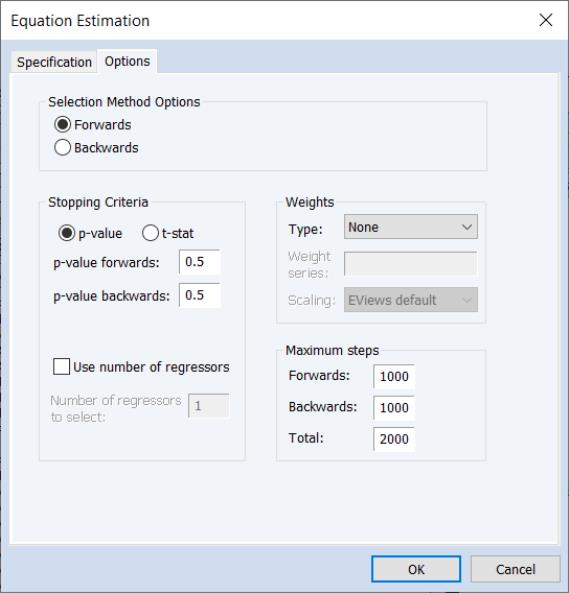
For the and methods you may specify the direction of the method using the and radio buttons and to provide a using either a p-value or t-statistic tolerance for adding or removing variables.
You may also choose to stop the procedures once they have added or removed a specified number of regressors by selecting the option and providing a number of the corresponding edit field.
The portion of the dialog is the same as that used in other estimators such as least squares. For more information, please see
“Weighted Least Squares”.
Swapwise Options
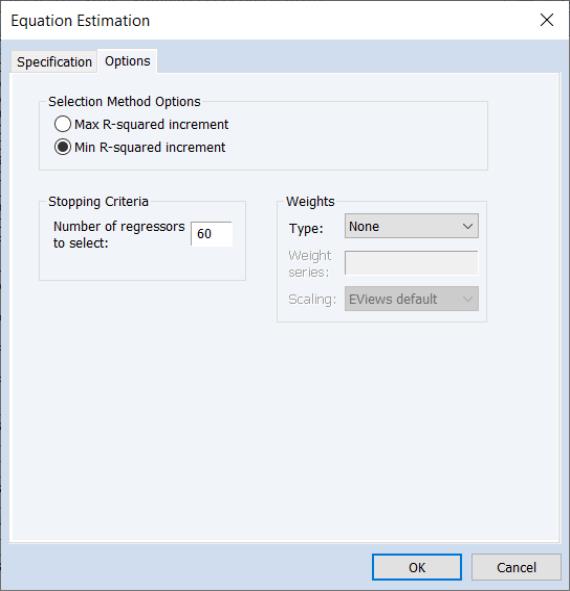
The Swapwise variable selection method lets you choose whether you wish to use Max R-squared Increment or Min R-squared Increment, and to enter the number of additional variables to be selected.
By default, the number of additional variables is set to one so that if you do not enter a value, EViews will select the single variable that will lead to the largest increase in R-squared.
The portion of the dialog is the same as that used in other estimators such as least squares. For more information, please see
“Weighted Least Squares”.
Combinatorial Options
The combinatorial options page simply prompts you to provide the number of additional variables.
By default, the number of additional variables is set to one so that if you do not enter a value, EViews will select the single variable that will lead to the largest increase in R-squared
The portion of the dialog is the same as that used in other estimators such as least squares. For more information, please see
“Weighted Least Squares”.
Auto-Search / GETS Options
When is chosen as the on the tab, the tab will change to display options specific to the Auto-Search/GETS algorithm:
The options are divided into several sections.
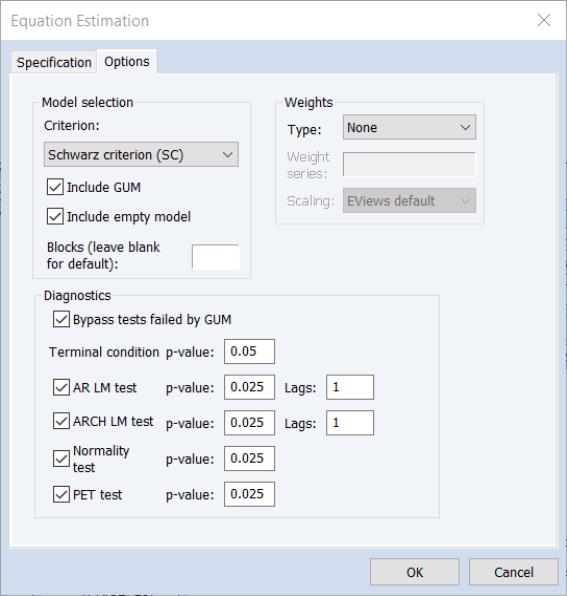
• The Model selection section offers options for the selection criteria used during the variable selection process. The Criteria dropdown specifies the information criteria used to select the final model from the candidates remaining in step 4) of the selection algorithm. The Include GUM and Include empty model checkboxes specify whether to include either the general model (i.e. the model with all possible search variables) or the empty model (the model with zero search variables) as candidates.
The Blocks edit field allows you to overwrite the EViews’ choice for the number of blocks into which to split the search variables if the number of search variables is greater than the number of observations.
• The
Diagnostics section identifies the options for the diagnostic tests used in the diagnostic tests steps 1) and 3) of the algorithm (
“Auto-Search / GETS”). The
Terminal condition p-value is used to set the
p-value against which the significance of the remaining variable is tested when determining whether to stop the selection process along a path in step 3).
The AR LM test, ARCH LM test, Normality test and PET test checkboxes are corresponding p-value edit fields are used to determine whether those tests are used when determining the validity of both the GUM and each selection model, and their associated p-value. For both the AR and ARCH LM tests, the number of lags used in the test may also be specified.
The portion of the dialog is the same as that used in other estimators such as least squares. For more information, please see
“Weighted Least Squares”.
Lasso Options
For Lasso selection, the there are two options dialog pages that allow you control the specification of the objective and the estimation method.
You may use the dialog pages to control the determination of the penalty parameter, to specify data transformation options, individual observation weights, and to control the iterative estimation procedure.
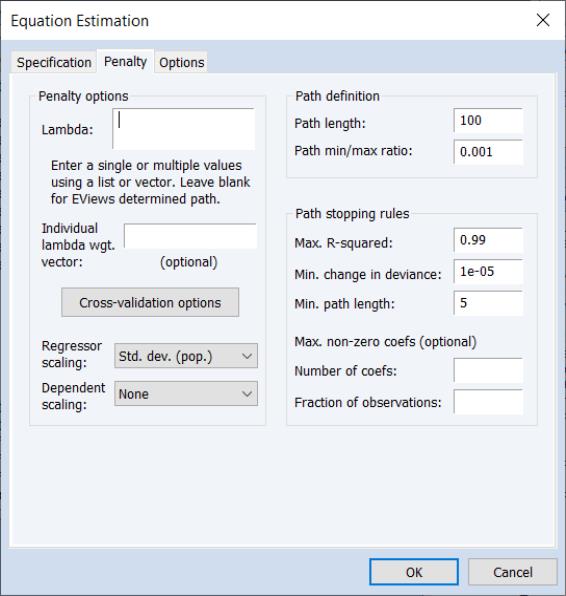
Penalty
There are three sections in this dialog: a section which contains options that affect the penalty calculations, a section which controls the automatic determination of a list of penalty values, and a rules section which controls the computation of estimates along the
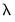
-path.
The section contains settings related to the computation of the penalty portion of the objective function:
• The edit field controls the overall penalty parameter
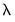
. You may enter a single value, multiple values in the form of a list of values and/or vector objects, or you may leave the edit field blank to have EViews automatically specify a list of values.
• A button provides settings for controlling the cross-validation model selection procedure when you have specified multiple
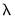
values in the edit field. See
“Cross-validation Options”.
• You may use the and drop-down menus to choose between: , , , , , and scaling.
The section contains settings for automatically determining a grid of
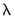
values using the approach outlined in
“Automatic Lambda Grid”:
• The edit field specifies the number of penalty values in the path.
• The specifies the smallest
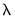
value as a fraction of the automatically determined largest value.
The describe settings for truncating path estimation (
“Path Stopping Rules”):
• The specifies the minimum number of values before applying the stopping rules.
• The edit field gives the value of the explained fraction of the null sums-of-squared residuals beyond which path estimation stops. EViews will truncate path estimation if fraction of null deviance explained is larger than this value.
• The gives the minimum level of relative change in the explained deviance (sums-of-squared residuals) required to continue path estimation. EViews will stop path estimation if the relative improvement is smaller than this value.
• The remaining two edit fields specify the maximum number of coefficients in levels () and as a fraction of the number of observations ().
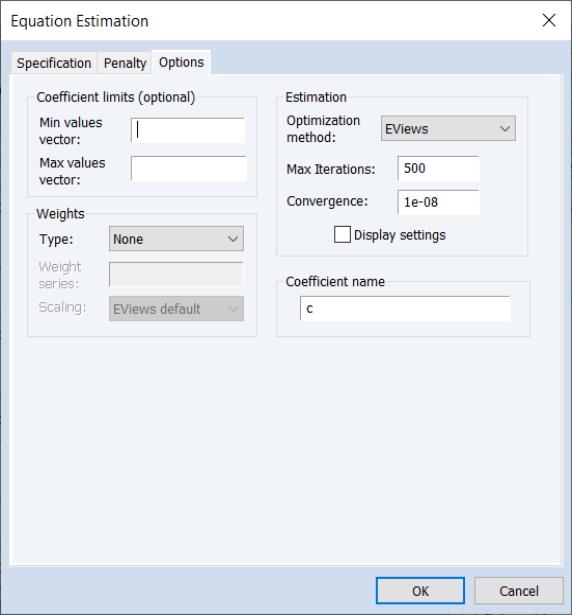
Options
The tab contains the remaining estimation settings. There are four sections: , , , and .
Most of these options will be familiar from other estimators. Note that coefficient minimum and maximum values may be specified using vectors or a scalar in the and edit fields.
The vectors containing the minimum non-positive and the maximum non-negative values should be sized to match the number of coefficients in the specification. Non-restricted coefficients are indicated using a NA in the corresponding vector element.
The allows you to choose between the , , and methods of estimating the Lasso (see
“Optimization Method” for discussion).