Graph Creation Object Summary
The graph creation commands may be used with the following EViews data objects:
area | |
band | |
bar | |
boxplot | |
distplot | |
dot | |
errbar | |
hilo | |
line | |
pie | |
qqplot | |
scat | |
scatmat | |
scatpair | |
seasplot | |
spike | |
xyarea | |
xybar | |
xyline | |
xypair | |
Display an area graph view.
Syntax
area(options) o1 [o2 o3 ... ]
object_name.area(options) [categorical_spec(arg)]
where o1, o2, ..., are series or group objects. Following the area keyword, you may specify general graph characteristics using options. Available options include multiple graph handling, dual scaling, template application, data contraction, adding axis extensions, and rotation.
The optional
categorical_spec allows you to specify a categorical graph (see
“Categorical Spec”).
Options
Scale options
a (default) | Automatic single scale. |
d | Dual scaling with no crossing. The first series or column is scaled on the left and all other series or columns are scaled on the right. |
x | Dual scaling with possible crossing. See the “d” option. |
n | Normalized scale (zero mean and unit standard deviation). May not be used with the “s” option. |
rotate | Rotate the graph so the observation axis is on the left. |
ab=type | Add axis border along data scale, where type may be “hist” or “h” (histogram), “boxplot” or “b”, “kernel” or “k”. (Note: axis borders are not available for panel graphs with “panel=” options that involve summaries: mean, median, etc.) |
Multiple series options (categorical graph settings will override these options)
m | Plot areas in multiple graphs (will override the “s” option). |
s | Stacked area graph. Each area represents the cumulative total of the series listed. The difference between areas corresponds to the value of a series. |
Template and printing options
o=template | Use appearance options from the specified template. template may be a predefined template keyword (“default” - current global defaults, “classic”, “modern”, “reverse”, “midnight”, “spartan”, “monochrome”) or a graph in the workfile. |
t=graph_name | Use appearance options and copy text and shading from the specified graph. |
b / -b | [Apply / Remove] bold modifiers of the base template style specified using the “o=” option above. |
w / -w | [Apply / Remove] wide modifiers of the base template style specified using the “o=” option above. |
reset | Resets all graph options to the global defaults. May be used to remove existing customization of the graph. |
p | Print the graph. |
The options which support the “–” may be preceded by a “+” or “–” indicating whether to turn on or off the option. The “+” is optional.
Graph data options
The following option is available in non-panel or categorical graph settings:
contract=key | Contract the data as specified by key, where key may be: “mean”, “median”, “max”, “min”, “sum”, “var” - variance, “sd” - standard deviation, “sumsq” - sum of the squared values, “skew” - skewness, “kurt” - kurtosis, “nas” - number of missing values, “obs” - number of observations, “unique” - error if the series is not identical for all observations in a given group, “first” - first observation in category using workfile order, “last” - last observation in category using workfile order, “quant(quantile)” - where quantile is a number between 0 and 1. |
Panel options
The following option applies when graphing panel structured data:
panel=arg (default taken from global settings) | Panel data display: “stack” (stack the cross-sections), “individual” or “i” (separate graph for each cross-section), “combine” or “c” (combine cross-section graphs in a single frame), “mean” (plot means across cross-sections), “median” (plot median across cross-sections). (Note: more general versions of these panel graphs may be constructed as categorical graphs.) |
Categorical graph options
These options only apply to categorical graphs (
“Categorical Spec”) where the graph has one or more
within factors and a contraction method other than raw data (see the
contract option above).
favorlegend | Favor the use of legends over axis labels to describe categories. |
elemcommon = int | Specifies the number of within factors for which the graph uses common area colors. For example, with multiple within dimensions, if “elemcommon=1”, then only categories defined by the first within factor will have common colors. If “elemcommon=2”, then categories defined by the first two within factors will have common colors. If “elemcommon=0”, all areas will have different colors. The default is one less than the number of within factors. |
Examples
Basic examples
area ser1 ser2 ser3
displays area graphs of SER1, SER2, and SER3.
group g1 ser1 ser2 ser3
g1.area(s)
defines a group G1 containing the three series SER1, SER2 and SER3, then plots a stacked area graph of the series in the group.
area(l, o=gra1) s1 gdp cons
creates an area graph of series S1, together with line graphs of GDP and CONS. The graph uses options from graph GRA1 as a template.
g1.area(o=midnight, b, w)
creates an area graph of the group G1, using the settings of the predefined template “midnight,” applying the bold and wide modifiers.
Panel examples
ser1.area(panel=individual)
displays area graphs with a separate graph for each cross-section, while,
ser1.area(panel=mean)
displays an area graph of the means for each period computed across cross-sections.
Categorical spec examples
ser1.area across(firm, dispname)
displays a categorical area graph of SER1 using distinct values of FIRM to define the categories. The graphs in multiple frames with the display names used as labels.
ser1.area across(firm, dispname, iscale)
shows the same graph with individual scaling for each of the frames.
ser1.area within(firm, inctot)
displays a graph with the same categorization (along with a category for the total), but with all of the graphs in a single frame.
Cross-references
See
“Graphing Data” for a detailed discussion of graphs in EViews, and
“Templates” for a discussion of graph templates.
See
Graph::graph for graph declaration and other graph types.
Display an area band graph view (if possible).
An area band graph fills the area between pairs of series or columns of a matrix.
Syntax
band(options) o1 [o2 o3 ... ]
object_name.band(options)
where o1, o2, ..., are series or group objects. Following the band keyword, you may specify general graph characteristics using options. Available options include axis settings and template application.
Options
Scale options
a (default) | Automatic single scale. |
d | Dual scaling with no crossing. The first series or column is scaled on the left and all other series or columns are scaled on the right. |
x | Dual scaling with possible crossing. See the “d” option. |
n | Normalized scale (zero mean and unit standard deviation). |
rotate | Rotate the graph so the observation axis is on the left. |
Template and printing options
o=template | Use appearance options from the specified template. template may be a predefined template keyword (“default” - current global defaults, “classic”, “modern”, “reverse”, “midnight”, “spartan”, “monochrome”) or a graph in the workfile. |
t=graph_name | Use appearance options and copy text and shading from the specified graph. |
b / -b | [Apply / Remove] bold modifiers of the base template style specified using the “o=” option above. |
w / -w | [Apply / Remove] wide modifiers of the base template style specified using the “o=” option above. |
reset | Resets all graph options to the global defaults. May be used to remove existing customization of the graph. |
p | Print the graph. |
The options which support the “–” may be preceded by a “+” or “–” indicating whether to turn on or off the option. The “+” is optional.
Panel options
The following option applies when graphing panel structured data:
panel=arg (default taken from global settings) | Panel data display: “stack” (stack the cross-sections), “individual” or “i” (separate graph for each cross-section), “combine” or “c” (combine cross-section graphs in a single frame), “mean” (plot means across cross-sections), “median” (plot median across cross-sections). (Note: more general versions of these panel graphs may be constructed as categorical graphs.) |
Examples
Basic examples
band upper1 lower1
displays a band graph using UPPER1 and LOWER1.
group g1 upper1 lower1 upper2 lower2
g1.band
plots a band graph with the UPPER1 and LOWER1 defining one band, and UPPER2 and LOWER2 defining as second band, both displayed in the same frame.
g1.band(o=midnight, l)
plots the band graph defined by UPPER1 and LOWER1 along with line graphs for UPPER2 and LOWER2, using the settings of the predefined template “midnight.”
Panel examples
g1.band
shows the band graph for the stacked data in a panel workfile.
g1.band(panel=individual)
displays band graphs for each cross-section in separate frames, while,
g1.band(panel=mean)
constructs a band graph using the means for each period computed across cross-sections.
Cross-references
See
“Graphing Data” for a detailed discussion of graphs in EViews, and
“Templates” for a discussion of graph templates.
See
Graph::graph for graph declaration and other graph types.
Display a bar graph.
(Note: when the individual bars in a bar graph become too thin to be distinguished, the graph will automatically be converted into an area graph; see
area.)
Syntax
bar(options) o1 [o2 o3 ... ]
object_name.bar(options) [categorical_spec(arg)]
where o1, o2, ..., are series or group objects. Following the bar keyword, you may specify general graph characteristics using options. Available options include multiple graph handling, dual scaling, template application, data contraction, adding axis extensions, and rotation.
The optional
categorical_spec allows you to specify a categorical graph (see
“Categorical Spec”).
Options
Scale options
a (default) | Automatic single scale. |
d | Dual scaling with no crossing. The first series or column is scaled on the left and all other series or columns are scaled on the right. |
x | Dual scaling with possible crossing. See the “d” option. |
n | Normalized scale (zero mean and unit standard deviation). May not be used with the “s” option. |
rotate | Rotate the graph so the observation axis is on the left. |
ab=type | Add axis border along data scale, where type may be “hist” or “h” (histogram), “boxplot” or “b”, “kernel” or “k”. (Note: axis borders are not available for panel graphs with “panel=” options that involve summaries: mean, median, etc.) |
Multiple series options (categorical graph settings will override these options)
m | Plot bars in multiple graphs (will override the “s” option). |
s | Stacked bar graph. Each bar represents the cumulative total of the series or columns listed. The difference between bars corresponds to the value of a series or column. |
Template and printing options
o=template | Use appearance options from the specified template. template may be a predefined template keyword (“default” - current global defaults, “classic”, “modern”, “reverse”, “midnight”, “spartan”, “monochrome”) or a graph in the workfile. |
t=graph_name | Use appearance options and copy text and shading from the specified graph. |
b / -b | [Apply / Remove] bold modifiers of the base template style specified using the “o=” option above. |
w / -w | [Apply / Remove] wide modifiers of the base template style specified using the “o=” option above. |
reset | Resets all graph options to the global defaults. May be used to remove existing customization of the graph. |
p | Print the graph. |
The options which support the “–” may be preceded by a “+” or “–” indicating whether to turn on or off the option. The “+” is optional.
Graph data options
The following option is available in non-panel or categorical graph settings:
contract=key | Contract the data as specified by key, where key may be: “mean”, “median”, “max”, “min”, “sum”, “var” - variance, “sd” - standard deviation, “sumsq” - sum of the squared values, “skew” - skewness, “kurt” - kurtosis, “nas” - number of missing values, “obs” - number of observations, “unique” - error if the series is not identical for all observations in a given group, “first” - first observation in category using workfile order, “last” - last observation in category using workfile order, “quant(quantile)” - where quantile is a number between 0 and 1. |
Panel options
The following option applies when graphing panel structured data:
panel=arg (default taken from global settings) | Panel data display: “stack” (stack the cross-sections), “individual” or “i” (separate graph for each cross-section), “combine” or “c” (combine cross-section graphs in a single frame), “mean” (plot means across cross-sections), “median” (plot median across cross-sections). (Note: more general versions of these panel graphs may be constructed as categorical graphs.) |
Categorical graph options
These options only apply to categorical graphs (
“Categorical Spec”) where the graph has one or more
within factors and a contraction method other than raw data (see the
contract option above).
favorlegend | Favor the use of legends over axis labels to describe categories. |
elemcommon = int | Specifies the number of within factors for which the graph uses common area colors. For example, with multiple within dimensions, if “elemcommon=1”, then only categories defined by the first within factor will have common colors. If “elemcommon=2”, then categories defined by the first two within factors will have common colors. If “elemcommon=0”, all areas will have different colors. The default is one less than the number of within factors. |
Examples
Basic examples
bar(p,rotate) oldsales newsales
displays and prints a rotated bar graph of the series OLDSALES and NEWSALES.
pop.bar
displays a bar graph of the series POP.
group mygrp oldsales newsales
mygrp.bar(s)
displays a stacked bar graph view of the series in the group MYGRP.
mygrp.bar(l, x, o=mybar1)
plots a bar graph of OLDSALES together with a line graph of NEWSALES. The bar graph is scaled on the left, while the line graph is scaled on the right. The graph uses options from graph MYBAR1 as a template.
mygrp.bar(o=midnight, b)
creates a bar graph of MYGRP, using the settings of the predefined template “midnight,” applying the bold modifier.
mygrp.bar(rotate, contract=mean)
displays a rotated bar graph of the means of OLDSALES and NEWSALES.
Panel examples
ser1.bar(panel=individual)
displays bar graphs for each cross-section in a separate frame, while,
ser1.bar(panel=median)
displays a bar graph of the medians of SER1 computed for each period across cross-sections.
Categorical spec examples
ser1.bar across(firm, dispname)
displays a categorical bar graph of SER1 using distinct values of FIRM to define the categories, and displaying the resulting graphs in multiple frames.
ser1.bar across(firm, dispname, iscale)
shows the same graph with individual scaling for each of the frames.
ser1.bar within(contract=mean, firm, inctot, label=value)
displays a graph of mean values of SER1 categorized by firm (along with an added category for the total), with all of the graphs in a single frame and the FIRM category value used as labels.
ser1.bar(contract=sum) across(firm, dispname) within(income, bintype=quant, bincount=4)
constructs a categorical bar graph of the sum of SER1 values within a category. Different firms are displayed in different graph frames, using the display name as labels, with each frame containing bars depicting the sum of SER1 for each income quartiles.
ser1.bar(contract=mean, elemcommon=1) within(sex) within(union)
creates a bar graph of mean values of within categories based on both SEX and UNION. Categories for the distinct elements of UNION will be depicted using different bar colors, with the color assignment repeated for different values of SEX.
group mygrp oldsales newsales
mygrp.bar(contract=min) within(@series) within(age)
displays bar graphs of the minimum values for categories defined by distinct values of AGE (and the two series). All of the bars will be displayed in a single frame with the bars for OLDSALES grouped together followed by the bars for NEWSALES.
mygrp.bar(contract=median, elemcommon=2) across(firm) across(@series) across(age)
also adds an additional categorization using the FIRM identifiers. The observations for a given firm are grouped together. Within a firm, the bars for the OLDSALES and NEWSALES, which will be depicted using different colors, will be grouped within each age category. The color assignment to OLDSALES and NEWSALES will be repeated across firms and ages (note that @SERIES is treated as the last across factor).
Cross-references
See
“Graphing Data” for a detailed discussion of graphs in EViews, and
“Templates” for a discussion of graph templates.
See
Graph::graphfor graph declaration and other graph types.
You may assign labels to the bars in (frozen) graph objects using the
Graph::options command
Display boxplots for each series or column.
Syntax
boxplot(options) o1 [o2 o3 ... ]
object_name.boxplot(options) [categorical_spec(arg)]
where o1, o2, ..., are series or group objects. You may specify general options after the boxplot keyword.
The optional
categorical_spec allows you to specify a categorical graph (see
“Categorical Spec”).
Options
q=arg | Set the quantile method, where arg can be: “r” - Rankit-Cleveland, “o” - Ordinary, “v” - van der Waerden, “b” - Blom, “t” - Tukey, “g” - Gumbel. |
rotate | Rotate the graph so the observation axis is on the left. |
Multiple series options (categorical graph settings will override these options)
m | Plot boxplots in multiple graphs. |
Panel options
The following option applies when graphing panel structured data:
panel=arg (default taken from global settings) | Panel data display: “stack” (stack the cross-sections), “individual” or “i” (separate graph for each cross-section), “combine” or “c” (compute cross-section graphs in a single frame). (Note: more general versions of these panel graphs may be constructed as categorical graphs.) |
Examples
Basic examples
wage.boxplot
displays boxplots for the series WAGE.
group g1 wage sex race
g1.boxplot
displays boxplots for WAGES, SEX and RACE in a single graph frame.
g1.boxplot(m, rotate)
places the rotated boxplots for each series in a separate frame.
Panel examples
ser1.boxplot(panel=individual)
displays boxplots for each cross-section in a separate frame, while,
ser1.boxplot(panel=stack)
displays a single boxplot computed from the stacked panel data.
ser1.boxplot(panel=combined, rotate)
shows rotated boxplots computed for each period (across cross-sections) in a single frame.
Categorical spec examples
ser1.boxplot across(firm, dispname)
displays a categorical boxplot graph of SER1 using distinct values of FIRM to define the categories, and displaying the resulting graphs in multiple frames with common scaling. Each frame is labeled using the FIRM display name.
ser1.boxplot across(firm, dispname, iscale)
constructs the same graph with individual scaling.
ser1.boxplot within(firm, label=value)
constructs a boxplot for each value of FIRM and displays the results in a single frame. The individual boxplots are labeled using the value of FIRM associated with the category.
ser1.boxplot across(firm) within(income, bintype=quant, bincount=4)
constructs a categorical boxplot with FIRM defining the across dimension, and INCOME defining the within dimension. Boxplots for each INCOME quartile of a given firm will be contained in a single frame, with different firms displayed in different frames.
grp1.boxplot within(sex) within(union)
creates an boxplot for within categories based on both SEX and UNION. Since we have not specified behavior for the implicit @SERIES in GRP1, each series in the group will be displayed in a separate frame, with individual scaling.
Cross-referencesC
See
“Boxplot” for a discussion of boxplots. See
“Graphing Data” for a detailed discussion of graphs in EViews, and
“Templates” for a discussion of graph templates.
See
Graph::graph for graph declaration and other graph types, and
Graph::setbpelem for a discussion of boxplot customization.
Displays a XY..YZ bubble plot.
At least three series must be present in the group. The first series will be plotted on the horizontal axis. The remaining series, aside from the last, will be plotted on the vertical axis. The last series will be used to determine the size of the bubbles.
Syntax
group_name.bubble(options)
Options
Multiple Y-Series options
m | Place bubble plots in multiple graphs (for groups containing more than three series). |
Examples
group g1 x ser1 ser2 ser3 ser4 z
g1.bubble
defines a group G1 containing the six series X, SER1, SER2, SER3, SER4, and Z, and then plots a bubble graph of the series in the group. X is on the horizontal axis, SER1, SER2, SER3, and SER4 are on the vertical axis, and the bubble size is determined by Z.
Cross-references
See
“Graphing Data” for a detailed discussion of graphs in EViews, and
“Templates” for a discussion of graph templates.
See
Graph::Graph for graph declaration and other graph types.
Display a bubble triplet plot.
Groups should contain series in multiples of three (triplets). Series not part of a triplet will be ignored. The first series of each triplet will be plotted on the horizontal axis. The second series of the triplet will be plotted on the vertical axis. The last series of the triplet will be used to determine the size of the bubbles.
Syntax
group_name.bubbletrip(options)
Options
Multiple Series Triplet Options
m | Place bubble plots in multiple graphs. (for groups containing more than two triplets or six series). |
Examples
group g1 x1 ser1 z1 x2 ser2 z2
g1.bubbletrip
defines a group G1 containing the two triplets or six series X1, SER1, Z1 and X2, SER2, Z2. It then plots a bubble graph X1 vs SER1, where Z1 is the bubble size, and X2 vs SER2, where Z2 is the bubble size.
Cross-references
See
“Graphing Data” for a detailed discussion of graphs in EViews, and
“Templates” for a discussion of graph templates.
See
Graph::Graph for graph declaration and other graph types.
Display a distribution graph.
Syntax
distplot(options) o1 [o2 o3 ... ]
object_name.distplot(options) analytical_spec(arg) [categorical_spec(arg)]
where o1, o2, ..., are series or group objects.
When used as a command, distplot only allows you to display the default histogram view.
When used as an object view, you must specify the type of distribution graph you wish to create in the
analytical_spec. You may select from: histogram, histogram polygon, histogram edge polygon, average shifted histogram, kernel density, theoretical distribution, empirical CDF, empirical survivor, empirical log survivor, or empirical quantile (see
“Analytical Spec”).
The optional
categorical_spec allows you to specify a categorical graph (see
“Categorical Spec”)
Options
Multiple series options
s | Plot in a single graph. (Categorical graph settings will override this option.) |
Template and printing options
o=template | Use appearance options from the specified template. template may be a predefined template keyword (“default” - current global defaults, “classic”, “modern”, “reverse”, “midnight”, “spartan”, “monochrome”) or a graph in the workfile. |
t=graph_name | Use appearance options and copy text and shading from the specified graph. |
b / -b | [Apply / Remove] bold modifiers of the base template style specified using the “o=” option above. |
w / -w | [Apply / Remove] wide modifiers of the base template style specified using the “o=” option above. |
reset | Resets all graph options to the global defaults. May be used to remove existing customization of the graph. |
p | Print the graph. |
The options which support the “–” may be preceded by a “+” or “–” indicating whether to turn on or off the option. The “+” is optional.
Panel options
The following option applies when graphing panel structured data.
panel=arg (default taken from global settings) | Panel data display: “stack” (stack the cross-sections), “individual” or “i” (separate graph for each cross-section). (Note: more general versions of these panel graphs may be constructed as categorical graphs.) |
Analytical Spec
Specify the distribution graph you wish to create in the analytical spec. For a description of distribution graphs, see
“Analytical Graph Types”. The analytical spec contains components of the form:
dist_type(dist_options)
where dist_type may be one of the following keywords:
hist | Histogram. |
freqpoly | Histogram Polygon. |
edgefreqpoly | Histogram Edge Polygon. |
ash | Average Shifted Histogram. |
kernel | Kernel Density |
theory | Theoretical Distribution. |
cdf | Empirical cumulative distribution function. |
survivor | Empirical survivor function. |
logsurvivor | Empirical log survivor function. |
quantile | Empirical quantile function. |
hist, freqpoly, edgefreqpoly, ash, kernel, and theory graphs may be combined in a single graph frame by providing multiple components.
Each distribution type has its own set of options, to be entered in dist_options:
Histogram, Histogram Polygon, Histogram Edge Polygon, and Avg. Shifted Histogram Options
scale=arg | arg specifies the scaling size, and may be “dens”, “freq”, or “relfreq”. (Note that the scaling setting is overridden if the histogram is displayed alongside a density, e.g., kernel density or theoretical distribution, plot.) |
binw=arg | arg specifies the bin width, and may be “eviews” (default), “sigma” (normal reference rule with 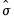 as the measure of dispersion), “iqr” (normal reference rule based on the interquartile range), “silverman” (normal reference rule with Silverman’s robust measure of dispersion), “freedman” (Freedman-Diaconis), “user” (user-specifed). |
binval=arg | arg specifies the numeric value of the bin width, when the option “binw=user” is specified. |
anchor=arg | arg specifies the anchor position. |
rightclosed | Right-closed bin intervals. |
nshifts=int (default=25) | Specifies the number of shift evaluations. (Only applies to average shifted histograms.) |
fill | Fill the graph. (Does not apply to the hist type.) |
nofill | Don’t fill the graph. (Does not apply to the hist type.) |
leg=arg | Specify the legend display settings, where arg can be: “def” - default, “n” - none, “s” - short, “det”- detailed. |
Histogram, Histogram Polygon, Histogram Edge Polygon, and Avg. Shifted Histogram Examples
inf.distplot hist
displays the default histogram view of the frequencies in each bin.
inf.distplot hist(scale=dens, anchor=100, binw=sigma)
constructs a density histogram computed using anchor position 100 and bin width determined by the normal reference rule using
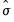
as the measure of dispersion.
group g1 inf unemp
g1.distplot hist(scale=relfreq)
displays a relative frequency histogram for the series in INF and UNEMP, each in their own graph frame, while:
g1.distplot(s) histpoly
displays the two frequency histograms in the same graph frame.
g1.distplot freqpoly(fill)
constructs filled frequency polygons for the series in G1, displayed in individual frames.
inf.distplot edgefreqpoly(leg=detailed)
shows the edge frequency polygon for INF with detailed legend entries.
g1.distplot ash(scale=dens, rightclosed, nshifts=100)
constructs average shifted density histograms using 100 shifts, with right-closed bins.
Kernel Options
k=arg (default=“e”) | Kernel type: “e” (Epanechnikov), “r” (Triangular), “u” (Uniform), “n” (Normal–Gaussian), “b” (Biweight–Quartic), “t” (Triweight), “c” (Cosinus). |
b=number | Specify a number for the bandwidth. |
b | Bracket bandwidth. |
ngrid=integer (default=100) | Number of grid points to evaluate. |
x | Exact evaluation. |
fill | Fill the area. |
nofill | Don’t fill the area. |
leg=arg | Specify the legend display settings, where arg can be: “def” - default, “n” - none, “s” - short, “det”- detailed. |
Kernel Examples
group gg weight height
gg.distplot kernel(ngrid=200, fill)
constructs kernel density estimates of HEIGHT and WEIGHT using 200 grid points and linear binning, and displays filled graphs in individual graph frames.
gg.displot(s) kernel(k=u, x)
computes the estimates using a uniform kernel with exact evaluation at each of the grid points, and displays the graphs in the same frame.
gg.displot kernel(leg=det)
displays the kernel plots along with detailed legend information.
Theory Options
dist=arg | arg can be: “normal”, “exp” - exponential, “logit” - logistic, “uniform” - uniform, “xman” - extreme max, “xmin” - extreme min, “chisq” - chi-squared, “pareto” - Pareto, “weibull” - Weibull, “gamma” - gamma, “tdist” - Student’s t-distribution. |
p1=int | Set first parameter. |
p2=int | Set second parameter. |
p3=int | Set third parameter. |
fill | Fill the area. |
nofill | Don’t fill the area. |
leg=arg | Specify the legend display settings, where arg can be: “def” - default, “n” - none, “s” - short, “det”- detailed. |
m=int | Set the iterations maximum. (Applies to logistic, extreme max, extreme min, chi-squared, Weibull, gamma or t-distributions.) |
c =int | Sets the convergence criterion. (Applies to logistic, extreme max, extreme min, chi-squared, Weibull, gamma or t-distributions.) |
s | Use user-specified starting values supplied in the C coefficient vector in the workfile (default uses EViews supplied starting values). (Applies to logistic, extreme max, extreme min, chi-squared, Weibull, gamma, or t-distributions.) |
Theory Examples
gdp50.distplot theory(leg=det)
displays a normal density plot fitted to the data in GDP50 with detailed legend information.
gdp50.distplot theory(p1=0)
fits a normal density using GDP50, restricting the mean of the distribution to be zero.
group gro1 weight height
gro1.distplot theory(dist=exp, fill)
constructs filled plots of the exponential densities fitted to the data in WEIGHT and HEIGHT, and displays them in separate frames.
gro1.distplot(s) theory(dist=weibull, p1=5, c=1e-5)
fits weibull densities to the data in the series setting the first parameter to 5 and estimating the second with a convergence tolerance of 1e-5. The graphs are displayed in a single frame.
Empirical CDF, Survivor, Log Survivor, and Quantile Options
q=arg | Set the quantile method, where arg can be: “r” - Rankit-Cleveland, “o” - Ordinary, “v” - van der Waerden, “b” - Blom, “t” - Tukey, “g” - Gumbel. |
n or noci | Do not include confidence intervals. |
ci=number (default=0.95) | Set confidence interval levels. |
leg=arg | Specify the legend display settings, where arg can be: “def” - default, “n” - none, “s” - short, “det”- detailed. |
Empirical CDF, Survivor, Log Survivor, and Quantile Examples
gdp50.distplot cdf
shows the cumulative distribution plot for GDP50, along with the default 95% confidence intervals.
gdp50.distplot survivor(noci)
displays the survivor plot for GDP50 without displaying confidence intervals.
group gro1 weight height
gro1.distplot logsurvivor(ci=0.9, leg=det)
displays the log-survivor plots for WEIGHT and HEIGHT along with 90% confidence intervals, and a detailed legend. The plots will be displayed in individual graph frames.
gro1.distplot(s) quantile
shows the quantile plots for WEIGHT and HEIGHT in the same graph frame.
Examples
Basic examples
distplot height weight length
displays default histograms for the three series.
group g1 age height weight length
g1.distplot hist(scale=dens, binw=sigma, leg=short) kernel theory
displays distribution plots for AGE, HEIGHT, WEIGHT, and LENGTH in separate frames, along with a short legend identifying each distribution plot. Each frame contains a histogram constructed using the
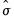
-normal reference rule, a kernel density plot, and a plot of the theoretical normal distribution fitted to the data. (Note that the “scale=dens” option in the
hist specification is redundant since combining a histogram with either the
kernel or
theory plot automatically sets the scaling.)
height.distplot theory theory(dist=weibull)
plots theoretical normal and weibull densities fit to the data in HEIGHT.
height.distplot quantile
displays a plot of the quantiles of height along with the confidence intervals.
g1.displot(s) cdf
plots the empirical CDF of the AGE, HEIGHT, WEIGHT, and LENGTH, and displays them in a single frame.
Panel examples
height.distplot(panel=individual) hist
displays histograms for each cross-section in separate frames while,
weight.distplot kern ash
displays a kernel density graph and average shifted histogram using the panel stacked WEIGHT data.
Categorical spec examples
height.distplot hist across(firm, dispname)
displays a categorical histogram graph of SER1 using distinct values of FIRM to define the categories, and displaying the resulting graphs in multiple frames.
height.distplot hist across(firm, dispname, iscale)
shows the same graph with individual scaling for each of the frames.
weight.distplot kernel ash within(firm, inctot, label=value)
displays kernel and average shifted histograms categorized by firm (with an added category for the total), with all of the graphs in a single frame and the category value used as labels.
length.distplot cdf across(firm, dispname) within(income, bintype=quant, bincount=4)
constructs a categorical cdf graph with FIRM defining the across dimension, and INCOME defining the within dimension. Observations will be classified in the within dimension using the quartiles of INCOME.
Cross-references
For a description of distribution graphs, see
“Analytical Graph Types”.
See
“Graphing Data” for a detailed discussion of graphs in EViews, and
“Templates” for a discussion of graph templates.
See
Graph::graph for graph declaration and other graph types
Display a dot plot graph view.
A dot plot is a symbol only version of the line and symbol graph that uses circles to represent the value of each observation.
Syntax
dot(options) o1 [o2 o3 ... ]
object_name.dot(options) [categorical_spec(arg)]
where o1, o2, ..., are series or group objects.
Following the dot keyword, you may specify general graph characteristics using options. Available options include multiple graph handling, dual scaling, template application, data contraction, adding axis extensions, and rotation.
The optional
categorical_spec allows you to specify a categorical graph (see
“Categorical Spec”).
Options
Scale options
a (default) | Automatic single scale. |
d | Dual scaling with no crossing. The first series or column is scaled on the left and all other series or columns are scaled on the right. |
x | Dual scaling with possible crossing. See the “d” option. |
n | Normalized scale (zero mean and unit standard deviation). May not be used with the “s” option. |
rotate | Rotate the graph so the observation axis is on the left. |
ab=type | Add axis border along data scale, where type may be “hist” or “h” (histogram), “boxplot” or “b”, “kernel” or “k”. (Note: axis borders are not available for panel graphs with “panel=” options that involve summaries: mean, median, etc.) |
Multiple series options (categorical graph settings will override these options)
m | Plot dot plots in multiple graphs (will override the “s” option). |
s | Stacked dot plot. Each dot represents the cumulative total of the series or columns listed. The difference between dots corresponds to the value of a series or column. |
Template and printing options
o=template | Use appearance options from the specified template. template may be a predefined template keyword (“default” - current global defaults, “classic”, “modern”, “reverse”, “midnight”, “spartan”, “monochrome”) or a graph in the workfile. |
t=graph_name | Use appearance options and copy text and shading from the specified graph. |
b / -b | [Apply / Remove] bold modifiers of the base template style specified using the “o=” option above. |
w / -w | [Apply / Remove] wide modifiers of the base template style specified using the “o=” option above. |
reset | Resets all graph options to the global defaults. May be used to remove existing customization of the graph. |
p | Print the graph. |
The options which support the “–” may be preceded by a “+” or “–” indicating whether to turn on or off the option. The “+” is optional.
Graph data options
The following option is available in non-panel or categorical graph settings:
contract=key | Contract the data as specified by key, where key may be: “mean”, “median”, “max”, “min”, “sum”, “var” - variance, “sd” - standard deviation, “sumsq” - sum of the squared values, “skew” - skewness, “kurt” - kurtosis, “nas” - number of missing values, “obs” - number of observations, “unique” - error if the series is not identical for all observations in a given group, “first” - first observation in category using workfile order, “last” - last observation in category using workfile order, “quant(quantile)” - where quantile is a number between 0 and 1. |
Panel options
The following option applies when graphing panel structured data:
panel=arg (default taken from global settings) | Panel data display: “stack” (stack the cross-sections), “individual” or “i” (separate graph for each cross-section), “combine” or “c” (combine cross-section graphs in a single frame), “mean” (plot means across cross-sections), “median” (plot median across cross-sections). (Note: more general versions of these panel graphs may be constructed as categorical graphs.) |
Categorical graph options
These options only apply to categorical graphs (
“Categorical Spec”) where the graph has one or more
within factors and a contraction method other than raw data (see the “contract” option above).
favorlegend | Favor the use of legends over axis labels to describe categories. |
elemcommon = int | Specifies the number of within factors for which the graph uses common area colors. For example, with multiple within dimensions, if “elemcommon=1”, then only categories defined by the first within factor will have common colors. If “elemcommon=2”, then categories defined by the first two within factors will have common colors. If “elemcommon=0”, all areas will have different colors. The default is one less than the number of within factors. |
Examples
Basic examples
dot(rotate) oldsales newsales
displays rotated dotplots of OLDSALES and NEWSALES.
pop.dot
displays a dotplot graph of the series POP.
group mygrp oldsales newsales
mygrp.dot(m)
displays dotplots of each series in MYGRP, each in its own frame.
mygrp.dot(o=midnight, b)
creates a bar graph of MYGRP, using the settings of the predefined template “midnight”, applying the bold modifier.
mygrp.dot(rotate, contract=median)
displays a rotated dotplot of the medians of OLDSALES and NEWSALES.
Panel examples
ser1.dot(panel=individual)
displays dotplots for each cross-section in a separate frame, while,
ser1.dot(panel=mean)
displays a dotplot of the means for each period computed across cross-sections.
ser1.dot(panel=combine)
shows the dotplots for each cross-section in the same graph frame, with different symbols and colors for each cross-section.
Categorical spec examples
ser1.dot across(firm, dispname)
displays a categorical dotplot graph of SER1 using distinct values of FIRM to define the categories, and displaying the resulting graphs in multiple frames.
ser1.dot across(firm, dispname, iscale)
shows the same graph with individual scaling for each of the frames.
ser1.dot within(firm, inctot, label=value)
displays a graph categorized by firm (with an added category for the total), with all of the graphs in a single frame and the category value used as labels.
ser1.dot across(firm, dispname) within(income, bintype=quant, bincount=4)
constructs a categorical dotplot graph with FIRM defining the across dimension, and INCOME defining the within dimension. Observations will be classified in the within dimension using the quartiles of INCOME.
ser1.dot(contract=mean, elemcommon=1) within(sex) within(union)
creates a dotplot of mean values of within categories based on both SEX and UNION. Categories within the more slowly varying SEX factor will be drawn using the same symbol and color, while the distinct elements of UNION will employ different symbols and colors.
Cross-references
See
“Graphing Data” for a detailed discussion of graphs in EViews, and
“Templates” for a discussion of graph templates.
See
Graph::graph for graph declaration and other graph types.
Display an error bar graph view (if possible).
If there are two series or columns, the error bar will show the high and low values in the bar. The optional third series or column will be plotted as a symbol.
Syntax
errbar(options) o1 o2 [o3 ...]
object_name.errbar(options)
where o1, o2, ..., are series or group objects.
Options
rotate | Rotate the graph so the observation axis is on the left. |
Template and printing options
o=template | Use appearance options from the specified template. template may be a predefined template keyword (“default” - current global defaults, “classic”, “modern”, “reverse”, “midnight”, “spartan”, “monochrome”) or a graph in the workfile. |
t=graph_name | Use appearance options and copy text and shading from the specified graph. |
b / -b | [Apply / Remove] bold modifiers of the base template style specified using the “o=” option above. |
w / -w | [Apply / Remove] wide modifiers of the base template style specified using the “o=” option above. |
reset | Resets all graph options to the global defaults. May be used to remove existing customization of the graph. |
p | Print the graph. |
The options which support the “–” may be preceded by a “+” or “–” indicating whether to turn on or off the option. The “+” is optional.
Panel options
The following option applies when graphing panel structured data:
panel=arg (default taken from global settings) | Panel data display: “stack” (stack the cross-sections), “individual” or “i” (separate graph for each cross-section), “combine” or “c” (combine cross-section graphs in a single frame), “mean” (plot means across cross-sections), “median” (plot median across cross-sections). (Note: more general versions of these panel graphs may be constructed as categorical graphs.) |
Examples
Basic examples
errbar xhigh xlow xval
displays an error bar graph using the series XLOW, XHIGH, and XVAL.
group g1 xhigh xlow xval
g1.errbar
creates an error bar graph view of the three series in G1.
g1.errbar(o=midnight, w)
displays an errbar bar graph using the settings of the predefined template “midnight”, applying the wide modifier.
Panel examples
g1.errbar(panel=individual)
displays error bars for each cross-section in a separate frame, while,
g1.errbar(panel=mean)
displays error bars formed by computing the means for the series across cross-sections.
Cross-references
See
“Graphing Data” for a detailed discussion of graphs in EViews, and
“Templates” for a discussion of graph templates.
See
Graph::graph for graph declaration and other graph types.
Display a high-low[-open-close] graph view (if possible).
Syntax
hilo(options) o1 o2 [o3 ...]
object_name.hilo(options)
where o1, o2, ..., are series or group objects. For a high-low[-open-close] graph, EViews uses the first series or column as the high series, the second series or column as the low series, and an optional third series or column as the close series. If four series or columns are provided, EViews will use them in the following order: high-low-open-close.
Note that if you wish to display a high-low-open graph, you should use an “NA”-series for the close values.
Options
rotate | Rotate the graph so the observation axis is on the left. |
Template and printing options
o=template | Use appearance options from the specified template. template may be a predefined template keyword (“default” - current global defaults, “classic”, “modern”, “reverse”, “midnight”, “spartan”, “monochrome”) or a graph in the workfile. |
t=graph_name | Use appearance options and copy text and shading from the specified graph. |
b / -b | [Apply / Remove] bold modifiers of the base template style specified using the “o=” option above. |
w / -w | [Apply / Remove] wide modifiers of the base template style specified using the “o=” option above. |
reset | Resets all graph options to the global defaults. May be used to remove existing customization of the graph. |
p | Print the graph. |
The options which support the “–” may be preceded by a “+” or “–” indicating whether to turn on or off the option. The “+” is optional.
Panel options
The following option applies when graphing panel structured data:
panel=arg (default taken from global settings) | Panel data display: “stack” (stack the cross-sections), “individual” or “i” (separate graph for each cross-section), “combine” or “c” (combine cross-section graphs in a single frame), “mean” (plot means across cross-sections), “median” (plot median across cross-sections). (Note: more general versions of these panel graphs may be constructed as categorical graphs.) |
Examples
Basic examples
hilo mshigh mslow msclose
displays a high-low-close graph using the series MSHIGH, MSLOW, and MSCLOSE.
group stockprice mshigh mslow msclose
stockprice.hilo(t=templt1)
displays a high-low-close graph of the series in STOCKPRICE, using the settings of the graph object TEMPLT1 as a template.
group g1 mshigh mslow msopen msclose
g1.hilo(p)
plots and prints the high-low-open-close graph of the four series in G1.
Panel examples
stockprice.hilo
displays the high-low-close graph for the stacked panel data.
stockprice.hilo(panel=individual)
displays high-low-close graphs for each cross-section in separate frames.
g1.hilo(panel=mean)
plots the high-low-open-close graph using the means for the series in every period computed across cross-sections.
Cross-references
See
“Graphing Data” for a detailed discussion of graphs in EViews, and
“Templates” for a discussion of graph templates.
See
Graph::graph for graph declaration and other graph types.
Display a line graph view.
Syntax
line(options) o1 [o2 o3 ... ]
object_name.line(options) [categorical_spec(arg)]
where o1, o2, ..., are series or group objects. Following the line keyword, you may specify general graph characteristics using options. Available options include multiple graph handling, dual scaling, template application, data contraction, adding axis extensions, and rotation.
The optional
categorical_spec allows you to specify a categorical graph (see
“Categorical Spec”).
Options
Scale options
a (default) | Automatic single scale. |
d | Dual scaling with no crossing. The first series or column is scaled on the left and all other series or columns are scaled on the right. |
x | Dual scaling with possible crossing. See the “d” option. |
n | Normalized scale (zero mean and unit standard deviation). May not be used with the “s” option. |
rotate | Rotate the graph so the observation axis is on the left. |
ab=type | Add axis border along data scale, where type may be “hist” or “h” (histogram), “boxplot” or “b”, “kernel” or “k”. (Note: axis borders are not available for panel graphs with “panel=” options that involve summaries: mean, median, etc.) |
wf | Use workfile frequency for linked series. |
Multiple series options (categorical graph settings will override these options)
m | Plot lines in multiple graphs (will override the “s” option). |
s | Stacked line graph. Each line represents the cumulative total of the series or columns listed. The difference between lines corresponds to the value of a series or column. |
Template and printing options
o=template | Use appearance options from the specified template. template may be a predefined template keyword (“default” - current global defaults, “classic”, “modern”, “reverse”, “midnight”, “spartan”, “monochrome”) or a graph in the workfile. |
t=graph_name | Use appearance options and copy text and shading from the specified graph. |
b / -b | [Apply / Remove] bold modifiers of the base template style specified using the “o=” option above. |
w / -w | [Apply / Remove] wide modifiers of the base template style specified using the “o=” option above. |
reset | Resets all graph options to the global defaults. May be used to remove existing customization of the graph. |
p | Print the graph. |
The options which support the “–” may be preceded by a “+” or “–” indicating whether to turn on or off the option. The “+” is optional.
Graph data options
The following option is available in non-panel or categorical graph settings:
contract=key | Contract the data as specified by key, where key may be: “mean”, “median”, “max”, “min”, “sum”, “var” - variance, “sd” - standard deviation, “sumsq” - sum of the squared values, “skew” - skewness, “kurt” - kurtosis, “nas” - number of missing values, “obs” - number of observations, “unique” - error if the series is not identical for all observations in a given group, “first” - first observation in category using workfile order, “last” - last observation in category using workfile order, “quant(quantile)” - where quantile is a number between 0 and 1. |
Panel options
The following option applies when graphing panel structured data:
panel=arg (default taken from global settings) | Panel data display: “stack” (stack the cross-sections), “individual” or “i” (separate graph for each cross-section), “combine” or “c” (combine cross-section graphs in a single frame), “mean” (plot means across cross-sections), “mean1se” (plot mean and +/- 1 standard deviation summaries), “mean2sd” (plot mean and +/- 2 s.d. summaries), “mean3sd” (plot mean and +/- 3 s.d. summaries), “meanfan” (plot the fan chart of all of the aforementioned s.d. summaries), “median” (plot median across cross-sections), “med25” (plot median and +/- 0.25 quantiles), “med10” (plot median and +/- 0.10 quantiles), “med05” (plot median +/- 0.05 quantiles), “med025” (plot median +/- 0.025 quantiles), “med005” (plot median +/- 0.005 quantiles), “medmxmn” (plot median, max and min), “medfan” (plot the fan chart of all the aforementioned quantiles). (Note: more flexible versions of the non-s.d. and on-quantile graphs may be constructed as categorical graphs.) |
Categorical graph options
These options only apply to categorical graphs (
“Categorical Spec”) where the graph has one or more
within factors and a contraction method other than raw data (see the
contract option above).
favorlegend | Favor the use of legends over axis labels to describe categories. |
elemcommon = int | Specifies the number of within factors for which the graph uses common area colors. For example, with multiple within dimensions, if “elemcommon=1”, then only categories defined by the first within factor will have common colors. If “elemcommon=2”, then categories defined by the first two within factors will have common colors. If “elemcommon=0”, all areas will have different colors. The default is one less than the number of within factors. |
Examples
Basic examples
line gdp cons m1
displays line graphs of the series GDP, CONST, and M1.
group g1 gdp cons m1
g1.line(d)
plots line graphs of the three series in group G1 with dual scaling (no crossing). The latter two series will share the same scale.
g1.line(m)
plots line graphs of the three series in group G1, with each plotted separately.
g1.line(o=midnight, b, w)
creates a line graph of the group G1, using the settings of the predefined template “midnight”, applying the bold and wide modifiers.
gdp.line(ab=boxplot)
displays the line graph with a boxplot displayed along the data dimension.
Panel examples
ser1.line(panel=individual)
displays area graphs with a separate graph for each cross-section, while,
ser1.line(panel=mean)
displays a line graph of the means for each period computed across cross-sections.
Categorical spec examples
ser1.line across(firm, dispname)
displays a categorical line graph of SER1 using distinct values of FIRM to define the categories, and displaying the resulting graphs in multiple frames using the display name in the labels.
ser1.line across(firm, dispname, iscale)
shows the same graph with individual scaling for each of the frames.
Cross-references
See
“Graphing Data” for a detailed discussion of graphs in EViews, and
“Templates” for a discussion of graph templates.
See
Graph::graph for graph declaration and other graph types.
Plots a graph with various graph types.
Syntax
group_name.mixed(options) type_list
The type_list argument controls the types of graphs included. Include a space delimited list of graph type keywords along with the series attached to that type. Available graph types are “line”, “bar”, “area”, “spike”, “band”, “stackedline”, “stackedbar”, “stackedarea”, and “stackedspike”.
Each keyword should be followed by parenthesis containing a comma separated list of series which will be graphed with that type. Series can be specified by name or by a number corresponding to their position in the group.
Options
llast/-llast | Draw all line types on top of all fill types (llast) or below all fill types (-llast). |
ab=type | Add axis border along data scale, where type may be “hist” or “h” (histogram), “boxplot” or “b”, “kernel” or “k”. (Note: axis borders are not available for panel graphs with “panel=” options that involve summaries: mean, median, etc.) |
Template and printing options
o=template | Use appearance options from the specified template. template may be a predefined template keyword (“default” - current global defaults, “classic”, “modern”, “reverse”, “midnight”, “spartan”, “monochrome”) or a graph in the workfile. |
t=graph_name | Use appearance options and copy text and shading from the specified graph. |
b / -b | [Apply / Remove] bold modifiers of the base template style specified using the “o=” option above. |
w / -w | [Apply / Remove] wide modifiers of the base template style specified using the “o=” option above. |
reset | Resets all graph options to the global defaults. May be used to remove existing customization of the graph. |
p | Print the graph. |
The options which support the “–” may be preceded by a “+” or “–” indicating whether to turn on or off the option. The “+” is optional.
Graph data options
The following option is available in non-panel or categorical graph settings:
contract=key | Contract the data as specified by key, where key may be: “mean”, “median”, “max”, “min”, “sum”, “var” - variance, “sd” - standard deviation, “sumsq” - sum of the squared values, “skew” - skewness, “kurt” - kurtosis, “nas” - number of missing values, “obs” - number of observations, “unique” - error if the series is not identical for all observations in a given group, “first” - first observation in category using workfile order, “last” - last observation in category using workfile order, “quant(quantile)” - where quantile is a number between 0 and 1. |
Panel options
The following option applies when graphing panel structured data:
panel=arg (default taken from global settings) | Panel data display: “stack” (stack the cross-sections), “individual” or “i” (separate graph for each cross-section), “combine” or “c” (combine cross-section graphs in a single frame), “mean” (plot means across cross-sections), “median” (plot median across cross-sections). (Note: more general versions of these panel graphs may be constructed as categorical graphs.) |
Examples
group g1 ser1 ser2 ser3 ser4
g1.mixed line(1,3) bar(2,4)
defines a group G1 containing the four series SER1, SER2, SER3, and SER4 then plots a mixed type graph of the series in the group, with SER1 and SER3 being shown in line graph form, and SER2 and SER4 in bar graph form.
g1.mixed(o=midnight,-lline) stackedarea(ser1, ser2) line(ser3) bar(4)
creates a mixed type graph of the group G1, using the settings of the predefined template “midnight,” applying the bold and wide modifiers. Series SER1 and SER2 are stacked into an area graph, whereas series SER3 is shown as a line and SER4 as a bar. The lines of SER3 are drawn behind the fill areas of SER1, SER2, and SER4.
Cross-references
See
“Graphing Data” for a detailed discussion of graphs in EViews, and
“Templates” for a discussion of graph templates.
See
Graph::graph for graph declaration and other graph types.
Display a pie chart view.
In the default setting, there will be one pie for each date or observation number. Each series or column of data is shown as a wedge in a different color/pattern, where the width of the wedge equals the percentage contribution of the series or column to the total of all listed series or columns. Negative and missing values are treated as zeros.
Syntax
pie(options) o1 o2 [o3 ... ]
object_name.pie(options) [categorical_spec(arg)]
where o1, o2, ..., are series or group objects. You may specify general graph characteristics by including options following the pie keyword.
The optional
categorical_spec allows you to specify a categorical graph (see
“Categorical Spec”).
Options
Template and printing options
o=template | Use appearance options from the specified template. template may be a predefined template keyword (“default” - current global defaults, “classic”, “modern”, “reverse”, “midnight”, “spartan”, “monochrome”) or a graph in the workfile. |
t=graph_name | Use appearance options and copy text and shading from the specified graph. |
b / -b | [Apply / Remove] bold modifiers of the base template style specified using the “o=” option above. |
w / -w | [Apply / Remove] wide modifiers of the base template style specified using the “o=” option above. |
reset | Resets all graph options to the global defaults. May be used to remove existing customization of the graph. |
p | Print the graph. |
The options which support the “–” may be preceded by a “+” or “–” indicating whether to turn on or off the option. The “+” is optional.
Graph data options
The following option is available in non-panel or categorical graph settings:
contract=key | Contract the data as specified by key, where key may be: “mean”, “median”, “max”, “min”, “sum”, “var” - variance, “sd” - standard deviation, “sumsq” - sum of the squared values, “skew” - skewness, “kurt” - kurtosis, “nas” - number of missing values, “obs” - number of observations, “unique” - error if the series is not identical for all observations in a given group, “first” - first observation in category using workfile order, “last” - last observation in category using workfile order, “quant(quantile)” - where quantile is a number between 0 and 1. |
Panel options
The following option applies when graphing panel structured data.
panel=arg (default taken from global settings) | Panel data display: “stack” (stack the cross-sections), “individual” or “i” (separate graph for each cross-section), “combine” or “c” (combine cross-section graphs in a single frame), “mean” (plot means across cross-sections), “median” (plot median across cross-sections). (Note: more general versions of these panel graphs may be constructed as categorical graphs.) |
Examples
Basic examples
pie const inv gov
displays pie charts for each period, each showing the relative sizes of CONS, INV, and GOV.
group g1 cons inv gov
g1.pie
displays the equivalent pie graph of the data in G1.
g1.pie(o=midnight, b, w)
displays the pie graph using the settings of the predefined template “midnight”, applying the bold and wide modifiers.
g1.pie(contract=mean)
displays a single pie graph with slices depicting the mean values for each series.
Panel examples
g1.pie(panel=individual)
displays pie graphs using the series in G1 with each cross-section displayed in a separate frame, while,
g1.pie(panel=mean)
displays a single pie graph showing, for each period, the pie graph formed using the means of the series computed across cross-sections.
Categorical examples
g1.pie(contract=mean) within(id)
constructs three pie graphs, one each for CONS, INV, and GOV, where the slices are determined by the relative sizes of the means of the respective series for each value of ID. There will be 10 slices for each pie.
g1.pie(contract=sum) within(id) within(@series)
displays a single pie graph with slices formed by the relative sizes of the sums of the series for each ID. If there are 10 distinct values of ID, the pie will have 30 slices.
for each value of ID using the sums of values of the series in the group G1 to determine the size of the pie slices. Each pie graph will be displayed in a separate frame. Alternately,
g1.pie(contract=mean) across(id) within(@series)
constructs one pie graph for each cross-section, where the slices are given by the mean values of CONS, INV, and GOV for the cross-section.
Cross-references
See
“Graphing Data” for a detailed discussion of graphs in EViews, and
“Templates” for a discussion of graph templates.
See
Graph::graph for graph declaration and other graph types.
Display a quantile-quantile graph.
Plots the (empirical) quantiles of a series or matrix column against either the quantiles of a theoretical distribution or the empirical quantiles of other series or columns in the group or matrix. You may specify the theoretical distribution and/or the method used to compute the empirical quantiles as options.
Syntax
qqplot(options) o1 [o2 o3 ... ]
object_name.qqplot(options) analytical_spec(arg) [categorical_spec(arg)]
where o1, o2, ..., are series or group objects.
When used as a command, qqplot displays the theoretical qq-plot against a fitted normal distribution.
When used to display the view of an object, you must specify a theoretical or empirical quantile graph in the
analytical_spec (see
“Analytical Spec”).
The optional
categorical_spec allows you to specify a categorical graph (see
“Categorical Spec”).
Options
Multiple series pair options (categorical graph settings will override these options)
s | Plot in a single graph (applies only to theoretical QQ and symmetry Q-Q graphs). |
mult= mat_type | Multiple series or column handling: where mat_type may be: “pairs” or “p” - pairs, “mat” or “m” - scatterplot matrix, “lower” or “l” - lower triangular matrix. |
Template and printing options
o=template | Use appearance options from the specified template. template may be a predefined template keyword (“default” - current global defaults, “classic”, “modern”, “reverse”, “midnight”, “spartan”, “monochrome”) or a graph in the workfile. |
t=graph_name | Use appearance options and copy text and shading from the specified graph. |
b / -b | [Apply / Remove] bold modifiers of the base template style specified using the “o=” option above. |
w / -w | [Apply / Remove] wide modifiers of the base template style specified using the “o=” option above. |
reset | Resets all graph options to the global defaults. May be used to remove existing customization of the graph. |
p | Print the graph. |
The options which support the “–” may be preceded by a “+” or “–” indicating whether to turn on or off the option. The “+” is optional.
Panel options
The following option applies when graphing panel structured data.
panel=arg (default taken from global settings) | Panel data display: “stack” (stack the cross-sections), “individual” or “i” (separate graph for each cross-section). (Note: more general versions of these panel graphs may be constructed as categorical graphs.) |
Analytical Spec
Specify the type of quantile-quantile graph you wish to create in the analytical spec. For a description of quantile-quantile graphs, see
“Analytical Graph Types”. The analytical spec should be in the form:
qq_type(type_options)
where qq_type may be one of the following keywords:
theory | Theoretical quantile-quantile plot. |
empirical | Empirical quantile-quantile plot (requires at least two series or columns of a matrix) |
symmetry | Quantile quantile symmetry plot. |
You may provide multiple theoretical qq-plot elements, but may not have more than one empirical qq-plot, nor may you mix the two.
Each type has its own set of options, to be entered in type_options:
Theoretical Options
dist=arg | arg can be: “normal”, “exp” - exponential, “logit” - logistic, “uniform” - uniform, “xman” - extreme max, “xmin” - extreme min, “chisq” - chi-squared, “pareto” - Pareto, “weibull” - Weibull, “gamma” - gamma, “tdist” - Student’s t-distribution. |
p1=int | Set first parameter. |
p2=int | Set second parameter. |
p3=int | Set third parameter. |
q = arg | Set the quantile method, where arg can be: “r” - Rankit-Cleveland, “o” - Ordinary, “v” - van der Waerden, “b” - Blom, “t” - Tukey, “g” - Gumbel. |
noline | Don’t display a fit line. |
m=int | Set the iterations maximum. (Applies to logistic, extreme max, extreme min, chi-squared, Weibull, gamma, or t-distributions.) |
c =int | Sets the convergence criterion. (Applies to logistic, extreme max, extreme min, chi-squared, Weibull, gamma, or t-distributions.) |
s | Use user-specified starting values, supplied in the C coefficient vector in the workfile (default uses EViews supplied starting values). (Applies to logistic, extreme max, extreme min, chi-squared, Weibull, gamma, or t-distributions.) |
leg=arg | Specify the legend display settings, where arg can be: “def” - default, “n” - none, “s” - short, “det”- detailed. |
Empirical Options
q=arg | Set the quantile method, where arg can be: “r” - Rankit-Cleveland, “o” - Ordinary, “v” - van der Waerden, “b” - Blom, “t” - Tukey, “g” - Gumbel. |
noline | Don’t display a regression line. |
leg=arg | Specify the legend display settings, where arg can be: “def” - default, “n” - none, “s” - short, “det”- detailed. |
Examples
Theoretical examples
qqplot(s) inf unemp
displays theoretical qq-plots for INF and UNEMP against fitted normal distributions in a single frame.
group g1 inf unemp
g1.qqplot theory
displays theoretical qqplots of INF and UNEMP compared with normal distributions fitted to the data in each series. The graphs include fit lines and are displayed in separate frames.
g1.qqplot(s) theory(dist=exp)
compares INF and UNEMP with fitted exponential distributions, and displays the graphs in a single frame.
g1.qqplot(s) theory(dist=exp, p1=5)
plots the series against the quantiles of an exponential distribution with parameter 5 in a single frame.
Empirical Examples
group g2 ser1 ser2 ser3 ser4
g2.qqplot empirical
displays empirical qqplots for pairs of series in G2. The default behavior is to plot the first series in the group (SER1) against the remaining series (SER2, SER3, and SER4). The graphs include fit lines and are displayed in separate graph frames.
g1.qqplot(mult=pair) empirical(noline)
displays qqplots of SER1 versus SER2 and SER3 versus SER4 in separate graph frames, without a regression line.
Categorical examples
g1.qqplot theory within(age)
displays theoretical qq-plots with the series in G1 treated as the within factor and @SERIES treated as the across factor. The qq-plots for each series in G1 will be displayed in separate frames, with multiple qq-plots for each AGE category shown in each frame.
g1.qqplot(mult=p) empirical across(age)
displays empirical qq-plots for categories of AGE in separate graph frames.
Cross-references
For a description of quantile-quantile graphs, see
“Analytical Graph Types”.
See
“Graphing Data” for a detailed discussion of graphs in EViews, and
“Templates” for a discussion of graph templates.
See
Graph::graph for graph declaration and other graph types.
Display a scatterplot (if possible).
A scatterplot graph plots the values of one series or column against another using symbols.
There must be at least two series or columns to create a scatterplot. By default, the first series or column will be located along the horizontal axis, and the remaining data on the vertical axis. You may optionally choose to plot the data in pairs, where the first two series or columns are plotted against each other, the second two series or columns are plotted against each other, and so forth, or to construct graphs using all possible pairs (or the lower triangular set of pairs).
Scatterplots are simply XY-line plots with symbols turned on and lines turned off (see
Graph::setelem).
Syntax
scat(options) o1 o2 [o3 ... ]
object_name.scat(options) [auxiliary_spec(arg)] [categorical_spec(arg)]
where o1, o2, ..., are series or group objects.
Following the scat keyword, you may specify general graph characteristics using options. Available options include plotting the data in pairs or in multiple graphs, template application, and adding axis extensions.
The optional
auxilary_spec allows you to add fit lines to the scatterplot (regression lines, kernel fit, nearest neighbor fit, orthogonal regression, and confidence ellipses; see
“Auxiliary Spec”).
The optional
categorical_spec allows you to specify a categorical graph (see
“Categorical Spec”).
Options
Scale options
a (default) | Automatic single scale. |
b | Plot series or columns in pairs (the first two against each other, the second two against each other, and so forth). |
d | Dual scaling with no crossing. |
x | Dual scaling with possible crossing. |
n | Normalized scale (zero mean and unit standard deviation). May not be used with the “s” option. |
ab=type | Add axis border along data scales, where type may be “hist” or “h” (histogram), “boxplot” or “b”, “kernel” or “k”. (Note: axis borders are not available for panel graphs with “panel=” options that involve summaries: mean, median, etc.) |
Multiple series pair options (categorical graph settings will override these options)
m | Place scatterplots in multiple graphs. |
mult=mat_type | Multiple series or column handling: where mat_type may be: “pairs” or “p” - pairs, “mat” or “m” - scatterplot matrix, “lower” or “l” - lower triangular matrix. (Using the “mat” or “lower” options is the same as using the
scatmat command; using the “pairs” option is the same as using
scatpair.) |
s | Stacked scatterplot graph. Each symbol represents the cumulative total of the series or columns listed. The difference between symbols corresponds to the value of a series or column. |
Template and printing options
o=template | Use appearance options from the specified template. template may be a predefined template keyword (“default” - current global defaults, “classic”, “modern”, “reverse”, “midnight”, “spartan”, “monochrome”) or a graph in the workfile. |
t=graph_name | Use appearance options and copy text and shading from the specified graph. |
b / -b | [Apply / Remove] bold modifiers of the base template style specified using the “o=” option above. |
w / -w | [Apply / Remove] wide modifiers of the base template style specified using the “o=” option above. |
reset | Resets all graph options to the global defaults. May be used to remove existing customization of the graph. |
p | Print the graph. |
The options which support the “–” may be preceded by a “+” or “–” indicating whether to turn on or off the option. The “+” is optional.
Note that use of the template option will override the symbol setting.
Graph data options
The following option is available in categorical graph settings:
contract=key | Contract the data as specified by key, where key may be: “mean”, “median”, “max”, “min”, “sum”, “var” - variance, “sd” - standard deviation, “sumsq” - sum of the squared values, “skew” - skewness, “kurt” - kurtosis, “nas” - number of missing values, “obs” - number of observations, “unique” - error if the series is not identical for all observations in a given group, “first” - first observation in category using workfile order, “last” - last observation in category using workfile order, “quant(quantile)” - where quantile is a number between 0 and 1. |
Panel options
The following option applies when graphing panel structured data.
panel=arg (default taken from global settings) | Panel data display: “stack” (stack the cross-sections), “individual” or “i” (separate graph for each cross-section), “combine” or “c” (combine cross-section graphs in a single frame), “mean” (plot means across cross-sections), “median” (plot median across cross-sections). |
Categorical graph options
These options only apply to categorical graphs (
“Categorical Spec”) where the graph has one or more
within factors and a contraction method other than raw data (see the
contract option above).
favorlegend | Favor the use of legends over axis labels to describe categories. |
elemcommon = int | Specifies the number of within factors for which the graph uses common area colors. For example, with multiple within dimensions, if “elemcommon=1”, then only categories defined by the first within factor will have common colors. If “elemcommon=2”, then categories defined by the first two within factors will have common colors. If “elemcommon=0”, all areas will have different colors. The default is one less than the number of within factors. |
Examples
Basic examples
scat(m) age height weight length
displays scatterplots with AGE on the horizontal and HEIGHT, WEIGHT and LENGTH on the vertical axis in multiple frames.
group g1 age height weight length
g1.scat
displays the same scatterplots in a single frame.
g1.scat(m, ab=hist)
displays the same information in multiple frames with histograms along the data axes.
g1.scat(mult=pairs) linefit
plots AGE against HEIGHT and WEIGHT against LENGTH (along with a regression fit line) in a single graph frame.
g1.scat(s, t=scat2)
displays a stacked scatterplot, using the graph object SCAT2 as a template.
g1.scat(d, ab=kernel)
shows a scatterplot with dual scales and no crossing, with kernel density plots along the borders.
Panel examples
g1.scat(panel=combined)
displays a scatterplot for the series in G1 in a single frame with observations for different cross-sections identified using different symbols and colors.
g1.scat(panel=individual)
draws each cross-section scatter in a different graph frame.
g1.scat(panel=stacked)
displays the same plot, but with observations drawn with common color and symbol.
g1.scat(panel=stacked, contract=mean) linefit kernfit
constructs a scatterplot using the mean values computed across cross-sections (for a given period) and displays it in a single graph frame, along with regression and kernel regression fits. The “panel=-stacked” option instructs EViews to display the observations using a single symbol type and color, and to fit lines using all of the data depicted in the graph.
Categorical examples
group cgrp income consumption
cgrp.scat within(sex)
displays a scatterplot categorized by values of sex, with both categories displayed in the same graph frame using different symbol types and colors.
cgrp.scat within(sex) kernfit linefit
displays the same graph along with linear and kernel regression fits for each category.
cgrp.scat(contract=mean) nnfit within(state)
computes mean values for the series in CGRP for each STATE category, and displays the results in a single graph frame along with a line depicting the linear regression fit to the mean values.
cgrp.scat across(state) within(sex) nnfit
displays scatterplots for data with each STATE value in different frames. Within each frame, the data for each value of SEX are depicted using different symbol types and colors, and a nearest neighbor regression is fit to observations in each category.
Cross-references
See
“Graphing Data” for a detailed discussion of graphs in EViews, and
“Templates” for a discussion of graph templates.
See
Graph::graph for graph declaration and other graph types.
For a description of the available fit lines, see
“Auxiliary Graph Types”.
See
xyline for a description of XY graphs.
Display a matrix of scatterplots.
The scatmat view forms pairs using all possible pairwise combinations for the series or columns and constructs a plot for each pair, using specialized positioning and axis labeling.
Scatterplots are simply XY-line plots with symbols turned on and lines turned off (see
Graph::setelem). The
scatmat graph type is equivalent to using
scat with the “mult=mat” or “mult=lower” option indicating that the data should be graphed using the full or lower-triangular matrix of pairs.
Syntax
scatmat(options) o1 o2 [o3 ... ]
object_name.scatmat(options) [auxiliary_spec(arg)]
where o1, o2, ..., are series or group objects.
Following the scatmat keyword, you may specify general graph characteristics using options. Available options include template application and adding axis extensions.
The optional
auxilary_spec allows you to add fit lines to the scatterplot (regression lines, kernel fit, nearest neighbor fit, orthogonal regression, and confidence ellipses; see
“Auxiliary Spec”).
Options
Scale options
a (default) | Automatic single scale. |
d | Dual scaling with no crossing. |
x | Dual scaling with possible crossing. |
n | Normalized scale (zero mean and unit standard deviation). |
ab=type | Add axis border along data scales, where type may be “hist” or “h” (histogram), “boxplot” or “b”, “kernel” or “k”. (Note: axis borders are not available for panel graphs with “panel=” options that involve summaries: mean, median, etc.) |
Multiple graph options
l | Plot lower triangular scatterplot matrix. |
Template and printing options
o=template | Use appearance options from the specified template. template may be a predefined template keyword (“default” - current global defaults, “classic”, “modern”, “reverse”, “midnight”, “spartan”, “monochrome”) or a graph in the workfile. |
t=graph_name | Use appearance options and copy text and shading from the specified graph. |
b / -b | [Apply / Remove] bold modifiers of the base template style specified using the “o=” option above. |
w / -w | [Apply / Remove] wide modifiers of the base template style specified using the “o=” option above. |
reset | Resets all graph options to the global defaults. May be used to remove existing customization of the graph. |
p | Print the graph. |
The options which support the “–” may be preceded by a “+” or “–” indicating whether to turn on or off the option. The “+” is optional.
Note that use of the template option will override the symbol setting.
Panel options
The following option applies when graphing panel structured data.
panel=arg (default taken from global settings) | Panel data display: “stack” (stack the cross-sections), “individual” or “i” (separate graph for each cross-section), “combine” or “c” (combine cross-section graphs in a single frame), “mean” (plot means across cross-sections), “median” (plot median across cross-sections). (Note: more general versions of these panel graphs may be constructed as categorical graphs.) |
Examples
Basic examples
scatmat weight height age
displays a
matrix of scatter plots for all pairs of the three series.
group g1 weight height age
g1.scatmat
displays the same graph using the named group G1.
g1.scatmat(l)
shows the portion of the matrix below the diagonal.
g1.scatmat(l, ab=hist, o=midnight)
displays the lower triangular matrix with histograms along the borders using the graph settings in the pre-defined template “midnight.”
Panel examples
g1.scatmat(panel=combined)
displays a scatterplot matrix using the series in G1 with observations for different cross-sections identified using different symbols and colors.
g1.scatmat(panel=stacked)
displays the same matrix, but with a common color and symbol.
g1.scatmat(panel=individual, l) linefit
displays a lower-triangular scatterplot matrix with regression fit for each cross-section, each in an individual frame.
Cross-references
See
“Graphing Data” for a detailed discussion of graphs in EViews, and
“Templates” for a discussion of graph templates. See
Graph::graph for graph declaration and other graph types.
For a description of the available fit lines, see
“Auxiliary Graph Types”.
See
xyline for XY graphs.
Display a scatterplot pairs graph (if possible).
The data will be plotted in pairs, where the first two series or columns are plotted against each other, the second two series or columns are plotted against each other, and so forth. If the number of series or columns is odd, the last one will be ignored.
Scatterplots are simply XY plots with symbols turned on and lines turned off (see
Graph::setelem). The
scatpair graph type is equivalent to using
scat with the “mult=pairs” option indicating that the data should be graphed in pairs.
Syntax
scatpair(options) o1 o2 [o3 ... ]
object_name.scatpair(options) [auxiliary_spec(arg)]
where o1, o2, ..., are series or group objects.
Following the scatpair keyword, you may specify general graph characteristics using options. Available options include plotting the data in multiple graphs, template application, and adding axis extensions.
The optional
auxilary_spec allows you to add fit lines to the scatterplot (regression lines, kernel fit, nearest neighbor fit, orthogonal regression, and confidence ellipses; see
“Auxiliary Spec”).
Options
Scale options
a (default) | Automatic single scale. |
d | Dual scaling with no crossing. |
x | Dual scaling with possible crossing. |
n | Normalized scale (zero mean and unit standard deviation). |
ab=type | Add axis border along data scales, where type may be “hist” or “h” (histogram), “boxplot” or “b”, “kernel” or “k”. (Note: axis borders are not available for panel graphs with “panel=” options that involve summaries: mean, median, etc.) |
Multiple series pair options
m | Place scatterplots in multiple graphs. |
Template and printing options
o=template | Use appearance options from the specified template. template may be a predefined template keyword (“default” - current global defaults, “classic”, “modern”, “reverse”, “midnight”, “spartan”, “monochrome”) or a graph in the workfile. |
t=graph_name | Use appearance options and copy text and shading from the specified graph. |
b / -b | [Apply / Remove] bold modifiers of the base template style specified using the “o=” option above. |
w / -w | [Apply / Remove] wide modifiers of the base template style specified using the “o=” option above. |
reset | Resets all graph options to the global defaults. May be used to remove existing customization of the graph. |
p | Print the graph. |
The options which support the “–” may be preceded by a “+” or “–” indicating whether to turn on or off the option. The “+” is optional.
Note that use of the template option will override the symbol setting.
Graph data options
The following option is available in categorical graph settings:
contract=key | Contract the data as specified by key, where key may be: “mean”, “median”, “max”, “min”, “sum”, “var” - variance, “sd” - standard deviation, “sumsq” - sum of the squared values, “skew” - skewness, “kurt” - kurtosis, “nas” - number of missing values, “obs” - number of observations, “unique” - error if the series is not identical for all observations in a given group, “first” - first observation in category using workfile order, “last” - last observation in category using workfile order, “quant(quantile)” - where quantile is a number between 0 and 1. |
Panel options
The following option applies when graphing panel structured data.
panel=arg (default taken from global settings) | Panel data display: “stack” (stack the cross-sections), “individual” or “i” (separate graph for each cross-section), “combine” or “c” (combine cross-section graphs in a single frame), “mean” (plot means across cross-sections), “median” (plot median across cross-sections). (Note: more general versions of these panel graphs may be constructed as categorical graphs.) |
Examples
Basic examples
scatpair weight height age length
displays a combined scatterplot with AGE on the horizontal and HEIGHT on the vertical axis, and with WEIGHT on the horizontal and LENGTH on the vertical axis.
group g1 weight height age length
g1.scatpair
displays the same graph using the named group G1.
g1.scatpair(m, ab=kern)
displays each scatterplot in a separate frame with kernel density plots along the borders.
g1.scatpair(t=scat2)
displays the pairwise scatterplots, using the graph object SCAT2 as a template.
g1.scatpair(d)
shows a scatterplot for the pairs with dual scales and no crossing.
Panel examples
g1.scatpair kernfit
shows the scatterplot of the stacked panel data for pairs of series in G1. The scatterplot will be drawn with a common symbol type and color for all observations, and the kernel fit will use all of the observations.
g1.scatpair(panel=individual) linefit
displays, in individual frames, scatterplot pairs with fitted regression lines for each of the cross-sections.
g1.scatpair(panel=combined) linefit
displays the cross-section scatterplots and regression lines in a single graph frame. Different symbols and colors will be used for each cross-section series pair in the graph.
g1.scatpair(panel=stacked, contract=mean) nnfit kernfit
displays a scatterplot matrix of the mean values for each period (computed across cross-sections) in a single graph frame, along with nearest neighbor and kernel regression fits for the means.
Categorical examples
group cgrp income consumption interest savings
cgrp.scatpair(d) within(sex)
displays a scatterplot pair graph (CONSUMPTION versus INCOME; and SAVINGS and INTEREST) categorized by values of sex, with observations displayed in the same graph frame using different symbols and colors to denote cross-sections, and dual scaling.
cgrp.scatpair(d) within(sex) kernfit linefit
displays the same scatterplot but with linear regression and kernel regression fits for the observations in each category for each pair of series.
cgrp.scatpair(d) across(state) within(sex) nnfit
displays scatterplots for observations in each STATE in different frames. Within each frame, observations are depicted using different symbols and colors to denote SEX, and a nearest neighbor regression is fit to observations in each category.
cgrp.scatpair(d, contract=mean) nnfit within(state)
computes mean values for the series in CGRP for each STATE, and displays paired scatterplots of the means, along with a line depicting the nearest neighbor regression fit to the means, in a single graph frame.
Cross-references
See
“Graphing Data” for a detailed discussion of graphs in EViews, and
“Templates” for a discussion of graph templates. See
Graph::graph for graph declaration and other graph types.
For a description of the available fit lines, see
“Auxiliary Graph Types”.
See
xyline for a description of XY graphs.
Display a seasonal line graph view.
seasplot displays a paneled line graph view of a series or column ordered by season. This view is only available for workfiles with quarterly, monthly, or semi-annual frequencies.
Syntax
seasplot(options) o1 [o2 o3 ... ]
object_name.seasplot(options)
where o1, o2, ..., are series or group objects.
Options
m | Plot seasons using multiple overlayed lines. |
Template and printing options
o=template | Use appearance options from the specified template. template may be a predefined template keyword (“default” - current global defaults, “classic”, “modern”, “reverse”, “midnight”, “spartan”, “monochrome”) or a graph in the workfile. |
t=graph_name | Use appearance options and copy text and shading from the specified graph. |
b / -b | [Apply / Remove] bold modifiers of the base template style specified using the “o=” option above. |
w / -w | [Apply / Remove] wide modifiers of the base template style specified using the “o=” option above. |
reset | Resets all graph options to the global defaults. May be used to remove existing customization of the graph. |
p | Print the bar graph. |
The options which support the “–” may be preceded by a “+” or “–” indicating whether to turn on or off the option. The “+” is optional.
Examples
seasplot ipnsa ipnsb
displays a paneled seasonal plot of the series IPNSA and IPNSB.
freeze(gra_ip) ipnsa.seasplot
creates a graph object named GAR_IP that contains the paneled seasonal line graph view of the series IPNSA.
freeze(gra_ip2) ipnsa.seasplot(m)
creates GRA_IP2 containing the multiple line seasonal graph view of the series.
Cross-references
See
“Seasonal Graphs” for a brief discussion of seasonal line graphs.
See
“Graphing Data” for a detailed discussion of graphs in EViews, and
“Templates” for a discussion of graph templates. See
Graph::graph for graph declaration and other graph types.
Display a spike graph view.
Syntax
spike(options) o1 [o2 o3 ... ]
object_name.spike(options) [categorical_spec(arg)]
where o1, o2, ..., are series or group objects.
Following the spike keyword, you may specify general graph characteristics using options. Available options include multiple graph handling, dual scaling, template application, data contraction, adding axis extensions, and rotation.
The optional
categorical_spec allows you to specify a categorical graph (see
“Categorical Spec”).
Options
Scale options
a (default) | Automatic single scale. |
d | Dual scaling with no crossing. The first series or column is scaled on the left and all other series or columns are scaled on the right. |
x | Dual scaling with possible crossing. See the “d” option. |
n | Normalized scale (zero mean and unit standard deviation). |
rotate | Rotate the graph so the observation axis is on the left. |
ab=type | Add axis border along data scale, where type may be “hist” or “h” (histogram), “boxplot” or “b”, “kernel” or “k”. (Note: axis borders are not available for panel graphs with “panel=” options that involve summaries: mean, median, etc.) |
Multiple series options (categorical graph settings will override these options)
m | Plot spikes in multiple graphs. |
Template and printing options
o=template | Use appearance options from the specified template. template may be a predefined template keyword (“default” - current global defaults, “classic”, “modern”, “reverse”, “midnight”, “spartan”, “monochrome”) or a graph in the workfile. |
t=graph_name | Use appearance options and copy text and shading from the specified graph. |
b / -b | [Apply / Remove] bold modifiers of the base template style specified using the “o=” option above. |
w / -w | [Apply / Remove] wide modifiers of the base template style specified using the “o=” option above. |
reset | Resets all graph options to the global defaults. May be used to remove existing customization of the graph. |
p | Print the spike graph. |
The options which support the “–” may be preceded by a “+” or “–” indicating whether to turn on or off the option. The “+” is optional.
Graph data options
The following option is available in non-panel or categorical graph settings:
contract=key | Contract the data as specified by key, where key may be: “mean”, “median”, “max”, “min”, “sum”, “var” - variance, “sd” - standard deviation, “sumsq” - sum of the squared values, “skew” - skewness, “kurt” - kurtosis, “nas” - number of missing values, “obs” - number of observations, “unique” - error if the series is not identical for all observations in a given group, “first” - first observation in category using workfile order, “last” - last observation in category using workfile order, “quant(quantile)” - where quantile is a number between 0 and 1. |
Panel options
The following option applies when graphing panel structured data:
panel=arg (default taken from global settings) | Panel data display: “stack” (stack the cross-sections), “individual” or “i” (separate graph for each cross-section), “combine” or “c” (combine cross-section graphs in a single frame), “mean” (plot means across cross-sections), “median” (plot median across cross-sections). (Note: more general versions of these panel graphs may be constructed as categorical graphs.) |
Categorical graph options
These options only apply to categorical graphs, which are described below and specified by the within and across categorical spec. The graph must have one or more within factors and a contraction method other than raw data (see the contract option above).
favorlegend | Favor the use of legends over axis labels to describe categories. |
elemcommon = int | Specifies the number of within factors for which the graph uses common area colors. For example, with multiple within dimensions, if “elemcommon=1”, then only categories defined by the first within factor will have common colors. If “elemcommon=2”, then categories defined by the first two within factors will have common colors. If “elemcommon=0”, all areas will have different colors. The default is one less than the number of within factors. |
Examples
Basic examples
spike(rotate, m) pop oldsales newsales
displays a rotated spike graph of the series POP, OLDSALES, and NEWSALES, with each series in a separate frame.
pop.spike
displays a spike graph of the series POP.
group mygrp oldsales newsales
mygrp.spike(l, x, o=mytpt)
plot a spike graph of OLDSALES together with a line graphs of NEWSALES. The spike graph is scaled on the left, while the line graph is scaled on the right. The graph uses options from the graph MYTPT as a template.
mygrp.spike(o=midnight, b)
creates a spike graph of MYGRP, using the settings of the predefined template “midnight.”
mygrp.spike(rotate, contract=mean)
displays a rotated spike graph of the means of the series in MYGRP.
Panel examples
ser1.spike(panel=individual)
displays spike graphs for each cross-section in a separate frame, while,
ser1.spike(panel=median)
displays a spike graph of the medians for each period computed across cross-sections.
Categorical spec examples
ser1.spike across(firm, dispname)
displays a categorical spike graph of SER1 using distinct values of FIRM to define the categories, and displaying the resulting graphs in multiple frames.
ser1.spike across(firm, dispname, iscale)
shows the same graph with individual scaling for each of the frames.
ser1.spike within(contract=mean, firm, inctot, label=value)
displays a spike graph of mean values of SER1 categorized by firm (along with an added category for the total), with all of the graphs in a single frame and the FIRM category value used as labels.
ser1.spike(contract=sum) across(firm, dispname) within(income, bintype=quant, bincount=4)
constructs a categorical spike graph of the sum of SER1 values within a category. Different firms are displayed in different graph frames, using the display name as labels, with each frame containing spikes depicting the sum of SER1 for each income quartiles.
group mygrp oldsales newsales
mygrp.spike(contract=min) within(@series) within(age)
displays spike graphs of the minimum values for categories defined by distinct values of AGE (and the two series). All of the spike will be displayed in a single frame with the spikes for OLDSALES grouped together followed by the spikes for NEWSALES.
g1.spike(o=midnight, b, w)
creates a spike graph of the group G1, using the settings of the predefined template “midnight”, applying the bold and wide modifiers.
Cross-references
See
“Graphing Data” for a detailed discussion of graphs in EViews, and
“Templates” for a discussion of graph templates.
See
Graph::graph for graph declaration and other graph types.
Display an XY area graph view (if possible).
An XY area graph plots the values of one series or column against another. It is similar to a XY line, but with the region between the line and the zero horizontal axis filled.
(Note that XY area graphs are typically employed only when data along the horizontal axis are ordered.)
There must be at least two series or columns to create an XY area graph. By default, the first series or column will be located along the horizontal axis, with the remaining data on the vertical axis. You may optionally choose to plot the data in pairs, where the first two series or columns are plotted against each other, the second two series or columns are plotted against each other, and so forth, or to construct graphs using all possible pairs (or the lower triangular set of pairs).
Syntax
xyarea(options) o1 o2 [o3 ... ]
object_name.xyarea(options)
where o1, o2, ..., are series or group objects.
Options
Scale options
a (default) | Automatic single scale. |
b | Plot series or columns in pairs (the first two against each other, the second two against each other, and so forth). |
d | Dual scaling with no crossing. |
x | Dual scaling with possible crossing. |
n | Normalized scale (zero mean and unit standard deviation). |
ab=type | Add axis border along data scales, where type may be “hist” or “h” (histogram), “boxplot” or “b”, “kernel” or “k”. (Note: axis borders are not available for panel graphs with “panel=” options that involve summaries: mean, median, etc.) |
Multiple series pair options (categorical graph settings will override these options)
m | Plot areas in multiple graphs. |
s | Stacked graph. Each line represents the cumulative total of the series or columns listed. The difference between lines corresponds to the value of a series or column. |
Template and printing options
o=template | Use appearance options from the specified template. template may be a predefined template keyword (“default” - current global defaults, “classic”, “modern”, “reverse”, “midnight”, “spartan”, “monochrome”) or a graph in the workfile. |
t=graph_name | Use appearance options and copy text and shading from the specified graph. |
b / -b | [Apply / Remove] bold modifiers of the base template style specified using the “o=” option above. |
w / -w | [Apply / Remove] wide modifiers of the base template style specified using the “o=” option above. |
reset | Resets all graph options to the global defaults. May be used to remove existing customization of the graph. |
p | Print the graph. |
The options which support the “–” may be preceded by a “+” or “–” indicating whether to turn on or off the option. The “+” is optional.
Panel options
The following option applies when graphing panel structured data:
panel=arg (default taken from global settings) | Panel data display: “stack” (stack the cross-sections), “individual” or “i” (separate graph for each cross-section), “combine” or “c” (combine cross-section graphs in a single frame), “mean” (plot means across cross-sections), “median” (plot median across cross-sections). (Note: more general versions of these panel graphs may be constructed as categorical graphs.) |
Examples
Basic examples
xyarea income sales
displays an XY-area graph with INCOME on the horizontal and SALES on the vertical axis.
group g1 income sales
g1.xyarea
plots the same graph using the named object G1.
g1.xyarea(ab=boxplot, t=gr1)
displays the graph with boxplots along the axes, using the template settings from the graph GR1.
Panel examples
g1.xyarea
displays an XY-area graph for the stacked panel data.
g1.xyarea(panel=individual)
displays XY-area graphs for each cross-section in separate graph frames.
g1.xyarea(panel=mean)
computes means for each period across cross-sections, then displays the XY-area graph for the mean data in a single graph frame. Note that only in a very narrow set of circumstances is this latter command likely to yield a sensible graph.
Cross-references
scat and
xyline are specialized forms of XY graphs.
See
“Graphing Data” for a detailed discussion of graphs in EViews, and
“Templates” for a discussion of graph templates.
See
Graph::graph for graph declaration and other graph types.
Display an XY bar graph view (if possible).
An XY bar graph displays the data in sets of three series or columns as a vertical bar. For a given observation, the values in the first two series or columns define a region along the horizontal axis, while the value in the third series or column defines the vertical height of the bar.
XY bar graphs may, for example, be used to construct variable width histograms.
Syntax
xybar(options) o1 o2 [o3 ... ]
object_name.xybar(options)
where o1, o2, ..., are series or group objects.
Options
n | Normalized scale (zero mean and unit standard deviation). |
Template and printing options
o=template | Use appearance options from the specified template. template may be a predefined template keyword (“default” - current global defaults, “classic”, “modern”, “reverse”, “midnight”, “spartan”, “monochrome”) or a graph in the workfile. |
t=graph_name | Use appearance options and copy text and shading from the specified graph. |
b / -b | [Apply / Remove] bold modifiers of the base template style specified using the “o=” option above. |
w / -w | [Apply / Remove] wide modifiers of the base template style specified using the “o=” option above. |
reset | Resets all graph options to the global defaults. May be used to remove existing customization of the graph. |
p | Print the graph. |
The options which support the “–” may be preceded by a “+” or “–” indicating whether to turn on or off the option. The “+” is optional.
Panel options
The following option applies when graphing panel structured data:
panel=arg (default taken from global settings) | Panel data display: “stack” (stack the cross-sections), “individual” or “i” (separate graph for each cross-section), “combine” or “c” (combine cross-section graphs in a single frame in single graph frame), “mean” (plot means across cross-sections), “median” (plot median across cross-sections). (Note: more general versions of these panel graphs may be constructed as categorical graphs.) |
Examples
Basic examples
xybar lowbin highbin height
plots an XY-bar graph using LOWBIN and HIGHBIN to define the bin ranges and HEIGHT to draw the corresponding bar height.
group g1 lowbin highbin height
g1.xybar
plots the same graph using the named object G1.
g1.xybar(t=t1)
displays the graph using the template settings from the graph object T1.
Panel examples
g1.xybar(panel=individual)
displays an XY-bar graph for each cross-section in an individual graph frame.
g1.xybar(panel=mean)
displays an XY-bar graph for the data formed by taking means across cross-sections for each period. Note that only in a very narrow set of circumstances is this latter command likely to yield a sensible graph.
Cross-references
scat,
xyarea,
xyline, and
xypair are specialized forms of XY graphs.
See
“Graphing Data” for a detailed discussion of graphs in EViews, and
“Templates” for a discussion of graph templates.
See
Graph::graph for graph declaration and other graph types.
Display an XY error bar graph view (if possible).
The data must be in the form of a multiple of four series or columns. The first series is the x-axis points. The second series is the high error bar and the third series is the low error bar. The fourth series or column is the data of interest plotted as a symbol.
Syntax
xyerrbar(options) o1 o2 o3 o4 [o5 ... ]
object_name.xyerrbar(options)
where o1, o2, o3, o4,... are series or group objects.
Options
Template and printing options
o=template | Use appearance options from the specified template. template may be a predefined template keyword (“default” - current global defaults, “classic”, “modern”, “reverse”, “midnight”, “spartan”, “monochrome”) or a graph in the workfile. |
t=graph_name | Use appearance options and copy text and shading from the specified graph. |
b / -b | [Apply / Remove] bold modifiers of the base template style specified using the “o=” option above. |
w / -w | [Apply / Remove] wide modifiers of the base template style specified using the “o=” option above. |
reset | Resets all graph options to the global defaults. May be used to remove existing customization of the graph. |
p | Print the graph. |
The options which support the “–” may be preceded by a “+” or “–” indicating whether to turn on or off the option. The “+” is optional.
Panel options
The following option applies when graphing panel structured data.
panel=arg (default taken from global settings) | Panel data display: “stack” (stack the cross-sections), “individual” or “i” (separate graph for each cross-section), “combine” or “c” (combine cross-section graphs in a single frame), “mean” (plot means across cross-sections), “median” (plot median across cross-sections). (Note: more general versions of these panel graphs may be constructed as categorical graphs.) |
Basic examples
xyerrbar open xhigh xlow xval
displays an error bar graph using the series XHIGH, XLOW, and XVAL against the OPEN series.
group g1 open xhigh xlow xval
g1.xyerrbar
creates an error bar graph view of the four series in G1.
g1.xyerrbar(o=magazine, w)
displays an xyerrbar graph using the settings of the predefined template “magazine,” applying the wide modifier.
Panel examples
g1.xyerrbar(panel=individual)
displays an xyerrbar graph for each cross-section in a separate frame.
g1.xyerrbar(panel=mean)
displays an xyerrbar graph formed by computing the means for the series across cross-sections.
Cross-references
See
“Graphing Data” for a detailed discussion of graphs in EViews, and
“Templates” for a discussion of graph templates.
See
Graph::graph for graph declaration and other graph types.
Display an XY line graph view (if possible).
There must be at least two series or columns to create an XY line graph. By default, the first series or column will be located along the horizontal axis, with the remaining data on the vertical axis. You may optionally choose to plot the data in pairs, where the first two series or columns are plotted against each other, the second two series or columns are plotted against each other, and so forth, or to construct graphs using all possible pairs (or the lower triangular set of pairs).
XY line graphs are simply XY plots with lines turned on and symbols turned off (see
Graph::setelem).
Syntax
xyline(options) o1 o2 [o3 ... ]
object_name.xyline(options) [auxiliary_spec(arg)] [categorical_spec(arg)]
where o1, o2, ..., are series or group objects.
Following the xyline keyword, you may specify general graph characteristics using options. Available options include plotting the data in pairs or in multiple graphs, template application, and adding axis extensions.
The optional
auxilary_spec allows you to add fit lines to the scatterplot (regression lines, kernel fit, nearest neighbor fit, orthogonal regression, and confidence ellipses; see
“Auxiliary Spec”).
The optional
categorical_spec allows you to specify a categorical graph (see
“Categorical Spec”).
Options
Scale options
a (default) | Automatic single scale. |
b | Plot series or columns in pairs (the first two against each other, the second two against each other, and so forth). |
d | Dual scaling with no crossing. |
x | Dual scaling with possible crossing. |
n | Normalized scale (zero mean and unit standard deviation). May not be used with the “s” option. |
ab=type | Add axis border along data scales, where type may be “hist” or “h” (histogram), “boxplot” or “b”, “kernel” or “k”. (Note: axis borders are not available for panel graphs with “panel=” options that involve summaries: mean, median, etc.) |
Multiple series pair options (categorical graph settings will override these options)
m | Plot XY lines in multiple graphs. |
mult=mat_type | Multiple series or column handling: where mat_type may be: “pairs” or “p” - pairs, “mat” or “m” - scatterplot matrix, “lower” or “l” - lower triangular matrix. (Using the “pairs” options is the same as using the
xypair command.) |
s | Stacked XY line graph. Each line represents the cumulative total of the series or columns listed. The difference between lines corresponds to the value of a series or column. |
Template and printing options
o=template | Use appearance options from the specified template. template may be a predefined template keyword (“default” - current global defaults, “classic”, “modern”, “reverse”, “midnight”, “spartan”, “monochrome”) or a graph in the workfile. |
t=graph_name | Use appearance options and copy text and shading from the specified graph. |
b / -b | [Apply / Remove] bold modifiers of the base template style specified using the “o=” option above. |
w / -w | [Apply / Remove] wide modifiers of the base template style specified using the “o=” option above. |
reset | Resets all graph options to the global defaults. May be used to remove existing customization of the graph. |
p | Print the graph. |
The options which support the “–” may be preceded by a “+” or “–” indicating whether to turn on or off the option. The “+” is optional.
Note that use of the template option will override the lines setting.
Graph data options
The following option is available in categorical graph settings:
contract=key | Contract the data as specified by key, where key may be: “mean”, “median”, “max”, “min”, “sum”, “var” - variance, “sd” - standard deviation, “sumsq” - sum of the squared values, “skew” - skewness, “kurt” - kurtosis, “nas” - number of missing values, “obs” - number of observations, “unique” - error if the series is not identical for all observations in a given group, “first” - first observation in category using workfile order, “last” - last observation in category using workfile order, “quant(quantile)” - where quantile is a number between 0 and 1. |
Panel options
The following option applies when graphing panel structured data.
panel=arg (default taken from global settings) | Panel data display: “stack” (stack the cross-sections), “individual” or “i” (separate graph for each cross-section), “combine” or “c” (combine cross-section graphs in a single frame), “mean” (plot means across cross-sections), “median” (plot median across cross-sections). (Note: more general versions of these panel graphs may be constructed as categorical graphs.) |
Examples
Basic examples
xyline age height weight length
displays XY-line plots with AGE on the horizontal and HEIGHT, WEIGHT and LENGTH on the vertical axis.
group g1 age height weight length
g1.xyline
displays the same graph using the named object G1.
g1.xyline(m, ab=hist)
displays the same information in multiple frames with histograms along the borders.
g1.xyline(s, t=scat2)
displays a stacked XY-line graph, using the graph object SCAT2 as a template.
g1.xyline(d)
shows XY-line plots with dual scales and no crossing.
Panel examples
g1.xyline(panel=combined)
displays XY-line for series in G1 in a single frame with lines for different cross-sections for a given pair identified using different symbols and colors.
g1.xyline(panel=individual)
displays the graphs for each of the cross-sections in a different frame.
g1.xyline(panel=stacked)
displays the same plot, but with lines drawn from the beginning of the stacked panel to the end.
Categorical examples
group cgrp income consumption
cgrp.xyline within(sex)
displays a scatterplot categorized by values of sex, with both categories displayed in the same graph frame using different symbols and colors.
cgrp.xyline(contract=mean) within(state)
computes mean values for the series in CGRP for each STATE category, and displays the results in a single graph frame using a single line to connect the mean values.
cgrp.xyline across(state) within(sex)
displays line plots for data with each STATE value in different frames. Within each frame, the data for each value of SEX are drawn as a separate line.
Cross-references
scat is a specialized form of an XY graph.
See
“Graphing Data” for a detailed discussion of graphs in EViews, and
“Templates” for a discussion of graph templates.
See
Graph::graph for graph declaration and other graph types.
Display an XY pairs graph (if possible).
The data will be plotted in pairs, where the first two series or columns are plotted against each other, the second two series or columns are plotted against each other, and so forth. If the number of series or columns is odd, the last one will be ignored.
XY line graphs are simply XY plots with lines turned on and symbols turned off (see
Graph::setelem). The
xypair graph type is equivalent to using
xyline with the “mult=pairs” option indicating that the data should be graphed in pairs.
Syntax
xypair(options) o1 o2 [o3 ... ]
object_name.xypair(options) [auxiliary_spec(arg)]
Following the xypair keyword, you may specify general graph characteristics using options. Available options include plotting the data in multiple graphs, template application, and adding axis extensions.
The optional
auxilary_spec allows you to add fit lines to the scatterplot (regression lines, kernel fit, nearest neighbor fit, orthogonal regression, and confidence ellipses; see
“Auxiliary Spec”).
Options
Scale options
a (default) | Automatic single scale. |
d | Dual scaling with no crossing. |
x | Dual scaling with possible crossing. |
n | Normalized scale (zero mean and unit standard deviation). |
ab=type | Add axis border along data scales, where type may be “hist” or “h” (histogram), “boxplot” or “b”, “kernel” or “k”. (Note: axis borders are not available for panel graphs with “panel=” options that involve summaries: mean, median, etc.) |
Multiple series pair options
m | Plot XY lines in multiple graphs. |
Template and printing options
o=template | Use appearance options from the specified template. template may be a predefined template keyword (“default” - current global defaults, “classic”, “modern”, “reverse”, “midnight”, “spartan”, “monochrome”) or a graph in the workfile. |
t=graph_name | Use appearance options and copy text and shading from the specified graph. |
b / -b | [Apply / Remove] bold modifiers of the base template style specified using the “o=” option above. |
w / -w | [Apply / Remove] wide modifiers of the base template style specified using the “o=” option above. |
reset | Resets all graph options to the global defaults. May be used to remove existing customization of the graph. |
p | Print the graph. |
The options which support the “–” may be preceded by a “+” or “–” indicating whether to turn on or off the option. The “+” is optional.
Note that use of the template option will override the pair and line settings.
Graph data options
The following option is available in categorical graph settings:
contract=key | Contract the data as specified by key, where key may be: “mean”, “median”, “max”, “min”, “sum”, “var” - variance, “sd” - standard deviation, “sumsq” - sum of the squared values, “skew” - skewness, “kurt” - kurtosis, “nas” - number of missing values, “obs” - number of observations, “unique” - error if the series is not identical for all observations in a given group, “first” - first observation in category using workfile order, “last” - last observation in category using workfile order, “quant(quantile)” - where quantile is a number between 0 and 1. |
Panel options
The following option applies when graphing panel structured data.
panel=arg (default taken from global settings) | Panel data display: “stack” (stack the cross-sections), “individual” or “i” (separate graph for each cross-section), “combine” or “c” (combine cross-section graphs in a single frame), “mean” (plot means across cross-sections), “median” (plot median across cross-sections). (Note: more general versions of these panel graphs may be constructed as categorical graphs.) |
Basic examples
xypair age height weight length
displays XY-line plots with AGE on the horizontal and HEIGHT on the vertical axis, and WEIGHT on the horizontal and LENGTH on the vertical axis.
group g1 age height weight length
g1.xypair
plots the same graph using the named object G1.
g1.xypair(m, ab=boxplot)
displays the same information in multiple frames with boxplots along the axes.
g1.xypair(t=scat2)
displays the XY-line pair graphs, using the graph object SCAT2 as a template.
g1.xypair(d, ab=hist)
shows the paired XY-line plots with dual scales and no crossing, and histograms along the borders.
Panel examples
g1.xypair(panel=combined)
displays XY-line graphs in a single frame, with different lines types and colors for different cross-sections pairs.
g1.xypair(panel=individual)
displays the graphs for each of each cross-section in a different frame.
g1.xypair(panel=stacked)
constructs a single frame graph with lines drawn from the beginning of the stacked panel to the end.
g1.xypair(panel=mean)
constructs line graphs for pairs of series using the mean values computed across cross-sections (for a given period), and displays them in a single frame.
Categorical examples
group cgrp income consumption sales revenue
cgrp.xypair within(sex)
displays a paired data line graphs categorized by values of sex, with both categories displayed in the same graph frame using different line types and colors.
cgrp.xypair(contract=mean) within(state)
computes mean values for the series in CGRP for each STATE category, and displays the results in a single graph frame.
cgrp.xypair across(state) within(sex)
displays line plots for data with each STATE value in different frames. Within each frame, the data for each value of SEX are drawn as a separate line.
Cross-references
scat and
xyline are specialized forms of XY graphs.
See
“Graphing Data” for a detailed discussion of graphs in EViews, and
“Templates” for a discussion of graph templates.
See
Graph::graph for graph declaration and other graph types.