Vector
Vector. (One dimensional array of numbers).
Vector Declaration
There are several ways to create a vector object. Enter the vector keyword (with an optional dimension) followed by a name:
vector scalarmat
vector(10) results
Alternatively, you may declare a vector using an assignment statement. The vector will be sized and initialized, accordingly:
vector(10) myvec = 3.14159
vector results = vec1
Vector Views
cov compute variance measures for the data in the vector.
edftest empirical distribution function tests.
hist descriptive statistics and histogram.
label label information for the vector object.
sheet spreadsheet view of the vector.
stats descriptive statistics.
statby statistics by classification.
testby equality test by classification.
Vector Procs
classify recode vector into classes defined by a grid, specified limits, or quantiles.
clearhist clear the contents of the history attribute.
copy creates a copy of the vector.
distdata save a matrix containing distribution plot data computed from the vector.
export export vector as Excel 2007 XLSX, CSV, tab-delimited ASCII text, RTF, HTML, Enhanced Metafile, PDF, TEX, or MD file on disk.
fill fill elements of the vector.
getglobalc copy the contents of the workfile C coefficient vector into the vector object.
import imports data from a foreign file into the vector object.
olepush push updates to OLE linked objects in open applications.
read (deprecated) import data from disk.
resample resample from the rows of the vector
.
resize resize the vector object.
setattr set the value of an object attribute.
setformat set the display format for the vector spreadsheet.
setglobalc copy the contents of the vector object into the workfile C coefficient vector.
setindent set the indentation for the vector spreadsheet.
setjust set the horizontal justification for all cells in the spreadsheet view of the vector object.
setwidth set the column width for the vector spreadsheet.
showlabels displays the custom row and column labels of a vector spreadsheet.
write export data to disk.
Vector Graph Views
Graph creation views are discussed in detail in
“Graph Creation Command Summary”.
area area graph of the vector.
bar bar graph of data against the row index.
line line graph of the data against the row index.
qqplot quantile-quantile graph.
Vector Data Members
String values
@attr("arg") string containing the value of the arg attribute, where the argument is specified as a quoted string.
@collabels string containing the column label of the vector.
@description string containing the Vector object’s description (if available).
@detailedtype string with the object type: “VECTOR”.
@displayname string containing the Vector object’s display name. If the Vector has no display name set, the name is returned.
@name string containing the Vector object’s name.
@remarks string containing the Vector object’s remarks (if available).
@rowlabels string containing the row labels of the vector.
@type string with the object type: “VECTOR”.
@updatetime string representation of the time and date at which the Vector was last updated.
Scalar values
(i) i-th element of the vector. Simply append “(i)” to the vector name (without a “.”).
@rows number of rows in the svector.
Vector values
@droprow(arg) Returns the vector with the rows defined by arg removed. arg may be an integer, vector of integers, string, or svector of strings. Integers correspond to row numbers so that, for example, arg = 2 specifies the second row. Strings correspond to row labels so that arg = "2" specifies the first row labeled “2”.
@irow(arg) Returns the indices for the rows defined by arg where arg is a string or svector of strings. The strings correspond to row labels so that arg = "2" specifies the first row labeled “2”.
@row(arg) Returns the rows defined by arg. arg may be an integer, vector of integers, string, or svector of strings. Integers correspond to row numbers so that, for example, arg = 2 specifies the second row. Strings correspond to row labels so that arg = "2" specifies the first row labeled “2”.
@t Returns transpose.
Recode the vector into classes defined by a grid, specified limits, or quantiles.
Syntax
vector_name.classify(options) spec @ outname [mapname]
You should follow the classify keyword with any desired options, a specification spec, the “@”-sign, the name to be given the output series, and optionally the name for a valmap object describing the classification.
The form for the specification spec will depend on which of the four supported methods for classification is employed (using the “method=” option).
• If the default “method=step” is employed, EViews will construct the classification using the set of intervals of size step from start through end. The spec specification is of the form
stepsize start end
where stepsize is a positive numeric value and start and end are numeric values. If start or end are explicitly set to NAs, EViews will use the corresponding minimum and maximum value of the data extended by 5% (e.g., 0.95*min or 1.05*max).
• If “method=bins”, EViews will construct the classification by dividing the range between start and end into a specified number of bins. The specification is of the form:
nbins start end
where nbins in the integer number of bins. Note that depending upon whether you have selected left or right-closed intervals (using the “rightclosed” option), observations with values equal to the start or end may fall out-of-range.
• Using “method=limits” specifies a classification using bins defined by a set of limit values. The spec is given by:
arg1 [arg2 arg3 ...]
where the arguments are limit values or EViews vector objects containing limit values. The first limit value defines the upper limit of the first interval, and the last limit value defines the lower limit of the last interval. Note that there must be at least one limit value and that the values need not be provided in ascending or descending order.
• If “method=quants” is given, EViews uses the specified number of quantiles for the data, specified as an integer value. The specification is:
nquants
where nquants is the integer for the number of quantiles. For deciles you should set nquants =10, for quartiles, nquants = 4.
Options
method=arg (default = “step”) | Method for determining classification values: “step”– create a grid from start through end using the stepsize; “bins” – create bins by dividing the region from start to end into a specified number of bins; “quants” – create bins using the quantile values; “limits” - create bins using the specified limit points. |
rightclosed | Bins formed using right-closed intervals. 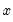 is defined to be in the bin from 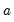 to 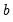 if 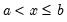 . The default is to use intervals closed on the left. |
rangeerr | Generate error if data value is found outside of defined bins. The default is to classify out-of-range values as NAs. |
q=arg (default=“r”) | Quantile calculation method. “b” (Blom), “r” (Rankit-Cleveland), “o” (Ordinary), “t” (Tukey), “v” (van der Waerden), “g” (Gumbel). Only relevant where “method=quants”. |
encode =arg (default=“index”) | Encoding method for output series: “index” – encode as integers from 0 to 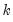 where 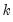 is the number of bins, where the 0 is reserved for NA encoding if “keepna” is specified; “left” – encode using the left-most value defining the bin; “right” – encode using the right-most value defining the bin; “mid” – encode using the midpoint of the bin. |
keepna | Classify NA values as 0 (for “encode=index” only). |
prompt | Force the dialog to appear from within a program. |
p | Print the results. |
Examples
vec1.classify 100 200 @ vec1_ct
classifies the values of VEC1 into bins of width 100 starting at 200 and ending at the data maximum times 1.05. The classification results are saved in the vector VEC1_CT.
vec1.classify(encode=right) 100 200 1100 @ vec1_ct1
classifies VEC1 into bins of size 100, from 200 through 1100. The output vector VEC1_CT1 will contain classification values taken from the right endpoints of the classification intervals. Rows with out-of-range values will be assign an NA.
vec1.classify(method=bins, rightclosed, rangeerr) 9 200 1100 @ vec1_ct2
defines 9 equally sized bins, starting at 200 and ending at 1100, and classifies the data into the vector VEC1_CT2. The bins are closed on the right, and out-of-range values will generate an error.
vec1.classify(method=quants, q=g, keepna) 4 @ vec1_ct3
classifies the values of VEC1 into quartiles (using the Gumbel definition) in the vector VEC1_CT3. Rows with NA values in VEC1 will be encoded as 0 in the output vector.
Cross-references
See
“Generate by Classification” for additional discussion.
Clear the column label in a vector object.
Syntax
vector_name.clearcollabels
Examples
vec1.clearcollabels
clears the custom column label from the vector VEC1.
Cross-references
Clear the contents of the history attribute for vector objects.
Removes the vector’s history attribute, as shown in the label view of the vector.
Syntax
vector_name.clearhist
Examples
v1.clearhist
v1.label
The first line removes the history from the vector V1, and the second line displays the label view of V1, including the now blank history field.
Cross-references
See
“Labeling Objects” for a discussion of labels and display names.
Clear the contents of the remarks attribute.
Removes the vector’s remarks attribute, as shown in the label view of the vector.
Syntax
vector_name.clearremarks
Examples
v1.clearremarks
v1.label
The first line removes the remarks from the vector V1, and the second line displays the label view of V1, including the now blank remarks field.
Cross-references
See
“Labeling Objects” for a discussion of labels and display names.
Clear the row labels in a vector object.
Syntax
vector_name.clearrowlabels
Examples
vec1.clearrowlabels
clears the custom row labels from the vector VEC1.
Cross-references
Creates a copy of the vector.
Creates either a named or unnamed copy of the vector.
Syntax
vector_name.copy
vector_name.copy dest_name
Examples
v1.copy
creates an unnamed copy of the vector V1.
v1.copy v2
creates V2, a copy of the vector V1.
Cross-references
Compute variance measures for the vector. You may compute measures related to Pearson product-moment (ordinary) variance, rank variance, or Kendall’s tau.
Syntax
vector_name.cov(options) [keywords [@partial z1 z2 z3...]]
You should specify keywords indicating the statistics you wish to display from the list below, optionally followed by the keyword @partial and the name of a conditioning matrix. In the matrix view setting, the columns of the matrix should contain the conditioning information, and the number or rows should match the original matrix.
You may specify keywords from one of the four sets (Pearson correlation, Spearman correlation, Kendall’s tau, Uncentered Pearson) corresponding the computational method you wish to employ. (You may not select keywords from more than one set.) Note that the Kendall’s tau measures are not particularly interesting since they generally will be equal, or nearly equal, to 1.
If you do not specify keywords, EViews will assume “cov” and compute the Pearson variance.
Pearson Correlation
cov | Product moment covariance. |
corr | Product moment correlation. |
sscp | Sums-of-squared cross-products. |
cases | Number of cases. |
obs | Number of observations. |
wgts | Sum of the weights. |
Spearman Rank Correlation
rcov | Spearman’s rank covariance. |
rcorr | Spearman’s rank correlation. |
rsscp | Sums-of-squared cross-products. |
cases | Number of cases. |
obs | Number of observations. |
wgts | Sum of the weights. |
Kendall’s tau
taub | Kendall’s tau-b. |
taua | Kendall’s tau-a. |
cases | Number of cases. |
obs | Number of observations. |
wgts | Sum of the weights. |
Uncentered Pearson
ucov | Product moment covariance. |
ucorr | Product moment correlation. |
usscp | Sums-of-squared cross-products. |
cases | Number of cases. |
obs | Number of observations. |
wgts | Sum of the weights. |
Note that cases, obs, and wgts are available for each of the methods.
Options
wgt=name (optional) | Name of series containing weights. |
wgtmethod=arg (default = “sstdev”) | Weighting method (when weights are specified using “weight=”): frequency (“freq”), inverse of variances (“var”), inverse of standard deviation (“stdev”), scaled inverse of variances (“svar”), scaled inverse of standard deviations (“sstdev”). Only applicable for ordinary (Pearson) calculations. Weights specified by “wgt=” are frequency weights for rank correlation and Kendall’s tau calculations. |
df | Compute covariances with a degree-of-freedom correction for the mean (for centered specifications), and any partial conditioning variables. |
outfmt=arg (default= “single”) | Output format: single table (“single”), multiple table (“mult”), list (“list”), spreadsheet (“sheet”). Note that “outfmt=sheet” is only applicable if you specify a single statistic keyword. |
out=name | Basename for saving output. All results will be saved in Sym matrices named using keys (“COV”, “CORR”, “SSCP”, “TAUA”, “TAUB”, “CONC” (Kendall’s concurrences), “DISC” (Kendall’s discordances), “CASES”, “OBS”, “WGTS”) appended to the basename (e.g., the covariance specified by “out=my” is saved in the Sym matrix “MYCOV”). |
prompt | Force the dialog to appear from within a program. |
p | Print the result. |
Examples
vec1.cov corr stat prob
displays a table containing the Pearson correlation, t-statistic for testing for zero correlation, and associated p-value, for the vector VEC1.
vec1.cov taub taustat tauprob
computes the Kendall’s tau-b, score statistic, and p-value for the score statistic.
Cross-references
For simple forms of the calculation see
@cov.
Display table, graph, or spool output in the vector object window.
Display the contents of a table, graph, or spool in the window of the vector object.
Syntax
vector_name.display object_name
Examples
vector1.display tab1
Display the contents of the table TAB1 in the window of the object VECTOR1.
Cross-references
Most often used in constructing an EViews Add-in. See
“Custom Object Output”.
Set display name for vector.
Attaches a display name to a vector which may be used to label output in tables and graphs in place of the standard vector name.
Syntax
vector_name.displayname display_name
Display names are case-sensitive, and may contain a variety of characters, such as spaces, that are not allowed in object names.
Examples
v1.displayname Coef Results
v1.label
The first line attaches a display name “Coef Results” to the vector V1, and the second line displays the label view of V1, including its display name.
v1.displayname Means by State
plot v1
The first line attaches a display name “Means by State” to the vector V1. The line graph view of V1 will use the display name as the legend.
Cross-references
See
“Labeling Objects” for a discussion of labels and display names.
Save a matrix containing distribution plot data computed from the vector.
Saves the data used to display a histogram, kernel density, theoretical distribution, empirical CDF or survivor plot, or quantile plot to the workfile.
Syntax
vector_name.distdata(dtype=dist_type, dist_options) matrix_name
saves the distribution plot data specified by dist_type, where dist_type must be one of the following keywords:
hist | Histogram (default). |
freqpoly | Histogram Polygon. |
edgefreqpoly | Histogram Edge Polygon. |
ash | Average Shifted Histogram. |
kernel | Kernel density |
theory | Theoretical distribution. |
cdf | Empirical cumulative distribution function. |
survivor | Empirical survivor function. |
logsurvivor | Empirical log survivor function. |
quantile | Empirical quantile function. |
theoryqq | Theoretical quantile-quantile plot. |
Options
The theoretical quantile-quantile plot type “theoryqq” takes the options described in
qqplot under
“Theoretical Options”.
For the remaining types,
dist_options are any of the distribution type-specific options described in
distplot.
Note that the graph display specific options such as “fill,” “nofill,” and “leg,” and “noline” are not relevant for this procedure.
You may use the “prompt” option to force the dialog display
prompt | Force the dialog to appear from within a program. |
Examples
rvec1.distdata(dtype=hist, anchor=0, scale=dens, rightclosed) matrix01
creates the data used to draw a histogram from the vector VEC1 with the anchor at 0, density scaling, and right-closed intervals, and stores that data in a matrix called MATRIX01 in the workfile.
vec1.distdata(dtype=kernel, k=b, ngrid=50, b=.5) matrix02
generates the kernel density data computed with a biweight kernel at 50 grid points, using a bandwidth of 0.5 and linear binning, and stores that data in MATRIX02.
vec1.distdata(dtype=theoryqq, q=o, dist=logit, p1=.5) matrix03
creates theoretical quantile-quantile data from VEC1 using the ordinary quantile method to calculate quantiles. The theoretical distribution is the logit distribution, with the location parameter set to 0.5. The data is saved into the matrix MATRIX03.
Cross-references
For a description of distribution graphs and quantile-quantile graphs, see
“Analytical Graph Types”.
See also
distplot and
qqplot.
Computes goodness-of-fit tests based on the empirical distribution function.
Compute Kolmogorov-Smirnov, Lilliefors, Cramer-von Mises, Anderson-Darling, and Watson empirical distribution function tests.
Syntax
vector_name.edftest(options)
Options
General Options
dist=arg (default=”nomal”) | Distribution to test: “normal” (Normal distribution), “chisq” (Chi-square distribution), “exp” (Exponential distribution), “xmax” (Extreme Value - Type I maximum), “xmin” (Extreme Value Type I minimum), “gamma” (Gamma), “logit” (Logistic), “pareto” (Pareto), “uniform” (Uniform). |
p1=number | Specify the value of the first parameter of the distribution (as it appears in the dialog). If this option is not specified, the first parameter will be estimated. |
p2=number | Specify the value of the second parameter of the distribution (as it appears in the dialog). If this option is not specified, the second parameter will be estimated. |
p3=number | Specify the value of the third parameter of the distribution (as it appears in the dialog). If this option is not specified, the third parameter will be estimated. |
prompt | Force the dialog to appear from within a program. |
p | Print test results. |
Estimation Options
The following options apply if iterative estimation of parameters is required:
b | Use Berndt-Hall-Hall-Hausman (BHHH) algorithm. The default is Marquardt. |
m=integer | Maximum number of iterations. |
c=number | Set convergence criterion. The criterion is based upon the maximum of the percentage changes in the scaled coefficients. |
showopts / ‑showopts | [Do / do not] display the starting coefficient values and estimation options in the estimation output. |
s | Take starting values from the C coefficient vector. By default, EViews uses distribution specific starting values that typically are based on the method of the moments. |
Examples
The command
vec1.edftest
uses the default settings to test whether the data in the vector VEC1 comes from a normal distribution. Both the location and scale parameters are estimated from the data in VEC1.
vec1.edftest(type=chisq)
tests whether the data in VEC1 come from a
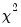
distribution with degrees-of-freedom estimated from the data.
freeze(tab1) vec1.edftest(type=chisq, p1=5)
tests whether the data in VEC1 comes from a
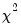
distribution with 5 degrees of freedom. The output is stored as a table object
TAB1.
Cross-references
See
“Empirical Distribution Tests” for a description of the goodness-of-fit tests.
Export vector to disk as an Excel 2007 XLSX, CSV, tab-delimited ASCII text, RTF, HTML, Enhanced Metafile, LaTeX, PDF, or Markdown file.
Syntax
vector_name.export(options) [path\]file_name
Follow the keyword with a name for the file. file_name may include the file type extension, or the file type may be specified using the “t=” option.
If an explicit path is not specified, the file will be stored in the default directory, as set in the global options.
The base syntax for writing Excel 2007 files is:
vector_name.export(options) [path\]file_name [table_description]
where the table_description may contain:
• “range = arg”, where arg is top left cell of the destination Excel workbook, following the standard Excel format [worksheet!][topleft_cell[:bottomright_cell]].
If the worksheet name contains spaces, it should be placed in single quotes. If the worksheet name is omitted, the cell range is assumed to refer to the currently active sheet. If only a top left cell is provided, a bottom right cell will be chosen automatically to cover the range of non-empty cells adjacent to the specified top left cell. If only a sheet name is provided, the first set of non-empty cells in the top left corner of the chosen worksheet will be selected automatically. As an alternative to specifying an explicit range, a name which has been defined inside the Excel workbook to refer to a range or cell may be used to specify the cells to read.
Options
t=file_type (default=“csv”) | Specifies the file type, where file_type may be one of: “excelxml” (Excel 2007 (xml)),“csv” (CSV - comma-separated), “rtf” (Rich-text format), “txt” (tab-delimited text), “html” (HTML - Hypertext Markup Language), “emf” (Enhanced Metafile), “pdf” (PDF - Portable Document Format), “tex” (LaTeX), or “md” (Markdown). Files will be saved with the “.xlsx”, “.csv”, “.rtf”, “.txt”, “.htm”, “.emf”, “.pdf”, “.tex”, or “.md” extensions, respectively. |
s=arg | Scale size, where arg is from 5 to 200, representing the percentage of the original table size (only valid for HTML or RTF files). |
n=string | Replace all cells that contain NA values with the specified string. “NA” is the default. |
h / -h | Include(/do not include) column and row headers. The default is to not include the headers |
prompt | Force the dialog to appear from within a program. |
PDF Options
landscape | Save in landscape mode (the default is to save in portrait mode). |
size=arg (default=“letter”) | Page size: “letter”, “legal”, “a4”, and “custom”. |
width=number (default=8.5) | Page width in inches if “size=custom”. |
height=number (default=11) | Page height in inches if “size=custom”. |
leftmargin=number (default=0.5) | Left margin width in inches. |
rightmargin=number (default = 0.5) | Right margin width in inches. |
topmargin=number (default=1) | Top margin width in inches. |
bottommargin= number (default = 1) | Bottom margin width in inches. |
LaTeX Options
texspec / -texspec | [Include / Do not include] the full LaTeX documentation specification in the LaTeX output. The default behavior is taken from the global default settings. |
Excel Options
mode=arg | Specify whether to create a new file, overwrite an existing file, or update an existing file. arg may be “create” (create new file only; error on attempt to overwrite) or “update” (update an existing file, only overwriting the area specified by the range= table_description). If the “mode=” option is not used, EViews will create a new file, unless the file already exists in which case it will overwrite it. Note that the “mode=update” option is only available for Excel in 1) Excel versions through 2003, if Excel is installed, and 2) Excel 2007 (xml). Note: Excel does not need to be installed for Excel 2007 writing. |
Excel 2007 Options
cellfmt=arg | Specify whether to use EViews, pre-existing, or remove cell formatting (colors, font, number formatting when possible, column widths and row heights) for the written range. arg may be “eviews” (replace current formatting in the file with the same cell formatting in EViews), “preserve” (leave current cell formatting already in the Excel file), or “clear” (remove current formatting and do not replace). |
strlen=arg (default = 256) | Specify the maximum the number of characters written for cells containing text. Strings in cells which are longer the max, will be truncated. |
Examples
The command:
vector1.export myvector
exports data in VECTOR1 to a CSV file named “myvector.CSV” in the default directory.
vector1.export(h,t=csv, n="NaN") myvector
saves the contents of VECTOR1 along with the column and row headers to a CSV (comma separated value) file named “myvector.CSV” and writes all NA values as “NaN”.
vector1.export(h,t=html, s=50) myvector
writes the data of VECTOR1 along with the column and row headers to a HTML file named “myvector.HTM” at half of the original size.
vector1.export(n=".", r=B) myvector
exports the data in the second column to a CSV file named “myvector.CSV”, and writes all NA values as “.”.
vector1.export(t=excelxml, cellfmt=clear, mode=update) myvector range=Country!b5
writes the data in VECTOR1 to the preexisting “myvector.XLSX” Excel file to the “Country” sheet at cell B5, where all cell formatting is cleared.
Cross-references
Fill a vector with the specified values.
Syntax
vector_name.fill(options) n1[, n2, n3 …]
Follow the keyword with a list of values to place in the specified object. Each value should be separated by a comma.
Running out of values before the object is completely filled is not an error; the remaining cells or observations will be unaffected, unless the “l” (loop) option is specified. If, however, you list more values than the vector can hold, EViews will not modify any observations and will return an error message.
Options
l | Loop repeatedly over the list of values as many times as it takes to fill the vector. |
o=integer (default=1) | Fill the vector starting from the specified element. Default is the first element. |
Examples
The following example declares a four element vector MC, initially filled with zeros. The second line fills MC with the specified values and the third line replaces from row 3 to the last row with –1.
vector(4) mc
mc.fill 0.1, 0.2, 0.5, 0.5
mc.fill(o=3, l) -1
Cross-references
See
“Matrix Language” for a detailed discussion of vector and matrix manipulation in EViews.
Compute frequency tables.
The freq command performs a one-way frequency tabulation.
Frequencies are computed for all of the rows in the vector. Rows with NAs are dropped unless included by option. You may use options to control automatic binning (grouping) of values and the order of the entries of the table.
Syntax
vector_name.freq(options)
Options
dropna (default) / keepna | [Drop/Keep] NA as a category. |
v=integer (default=1000) | Make bins if the number of distinct values or categories exceeds the specified number. |
nov | Do not make bins on the basis of number of distinct values; ignored if you set “v=integer.” |
a=number | (optional) Make bins if average count per distinct value is less than the specified number. |
b=integer (default=50) | Maximum number of categories to bin into if performing automatic binning. |
n, obs, count (default) | Display frequency counts. |
nocount | Do not display frequency counts. |
total (default) / nototal | [Display / Do not display] totals. |
pct (default) / nopct | [Display / Do not display] percent frequencies. |
cum (default) / nocum | (Display/Do not) display cumulative frequency counts/percentages. |
sort=arg (default=“lohi”) | Sort order for entries in the frequency table: high data value to low ("hilo"), low data value to high ("lohi" –default), high frequency to low ("freqhilo"), low frequency to high ("freqlohi"). |
prompt | Force the dialog to appear from within a program. |
p | Print the table. |
Examples
vec1.freq(nov, noa)
tabulates all values (no binning) of VEC1, with entries in ascending value order. The table will display counts, percentages, and cumulative frequencies.
vec1.freq(v=200, b=50, keepna, noa)
tabulates VEC1 including NAs. The observations will be binned if VEC1 has more than 200 distinct values; EViews will create at most 50 equal value-width bins. The number of bins may be smaller than 50.
vec1.freq(sort=freqhilo)
tabulates VEC1 with the table rows ordered from values with highest frequency to lowest.
Cross-references
See
“One-Way Tabulation” for a discussion of frequency tables.
Copy the contents of the workfile C coefficient vector into the vector object.
Syntax
vector_name.getglobalc
This function only applies to vectors, rowvectors and coef objects. The contents of the vector will be replaced with the first N elements of the workfile C coefficient vector, where N is the length of the vector object. This may be useful for storing starting values used in estimation.
Examples
vector(5) vec1
vec1.getglobalc
Creates a vector object with 5 rows, and then copies the first 5 elements of the C vector into it.
Histogram and descriptive statistics of a vector.
The hist command displays descriptive statistics and a histogram for the data in the vector.
Syntax
vector_name.hist(options)
Options
Examples
vec1.hist
Displays the histogram and descriptive statistics of VEC1.
Cross-references
See
“Histogram and Stats” for a discussion of the descriptive statistics reported in the histogram view.
See
distplot for a more fully-featured and customizable method of constructing histograms and
Vector::stats stats for a view with a more extensive set of basic descriptive statistics.
Imports data from a foreign file into the vector object.
Syntax
vector_name.import([type=]) source_description import_specification
• source_description should contain a description of the file from which the data is to be imported. The specification of the description is usually just the path and file name of the file, however you can also specify more precise information. See
wfopen for more details on the specification of
source_description.
• The optional “type=” option may be used to specify a source type. For the most part, you should not need to specify a “type=” option as EViews will automatically determine the type from the filename. The following table summaries the various source formats and along with the corresponding “type=” keywords:
| |
Excel (through 2003) | “excel” |
Excel 2007 (xml) | “excelxml” |
HTML | “html” |
Text / ASCII | “text” |
• import_specification can be used to provide additional information about the file to be read. The details of import_specification will depend upon the type of file being imported.
Excel Files
The syntax for reading Excel files is:
vector_name.import(type=excel[xml]) source_description [table_description] [variables_description]
The following table_description elements may be used when reading Excel data:
• “range = arg”, where arg is a range of cells to read from the Excel workbook, following the standard Excel format [worksheet!][topleft_cell[:bottomright_cell]].
If the worksheet name contains spaces, it should be placed in single quotes. If the worksheet name is omitted, the cell range is assumed to refer to the currently active sheet. If only a top left cell is provided, a bottom right cell will be chosen automatically to cover the range of non-empty cells adjacent to the specified top left cell. If only a sheet name is provided, the first set of non-empty cells in the top left corner of the chosen worksheet will be selected automatically. As an alternative to specifying an explicit range, a name which has been defined inside the excel workbook to refer to a range or cell may be used to specify the cells to read.
• “byrow”, transpose the incoming data. This option allows you to read files where the series are contained in rows (one row per series) rather than columns.
The optional variables_description may be formed using the elements:
• “colhead=int”, number of table rows to be treated as column headers.
• “types=("arg1","arg2",…)”, user specified data types of the series. If types are provided they will override the types automatically detected by EViews. You may use any of the following format keywords: “a” (character data), “f” (numeric data), “d” (dates), or “w” (EViews automatic detection). This option is rarely required.
• “na="arg1"”, text used to represent observations that are missing from the file. The text should be enclosed on double quotes.
• “scan=[int| all]”, number of rows of the table to scan during automatic format detection (“scan=all” scans the entire file).
• “firstobs=int”, first observation to be imported from the data (default is 1). This option may be used to start reading rows from partway through the table.
• “lastobs = int”, last observation to be read from the data (default is last observation of the file). This option may be used to read only part of the file, which may be useful for testing.
Excel Examples
vec_obj.import "c:\data files\data.xls"
loads the active sheet of DATA.XLSX into the VEC_NAME vector object.
vec_obj.import "c:\data files\data.xls" range="GDP data"
reads the data contained in the “GDP data” sheet of “Data.XLS” into the VEC_OBJ object.
HTML Files
The syntax for reading HTML pages is:
vector_name.import(type=html) source_description [table_description] [variables_description]
The following table_description elements may be used when reading an HTML file or page:
• “table = arg”, where arg specifies which HTML table to read in an HTML file/page containing multiple tables.
When specifying arg, you should remember that tables are named automatically following the pattern “Table01”, “Table02”, “Table03”, etc. If no table name is specified, the largest table found in the file will be chosen by default. Note that the table numbering may include trivial tables that are part of the HTML content of the file, but would not normally be considered as data tables by a person viewing the page.
• “skip = int”, where int is the number of rows to discard from the top of the HTML table.
• “byrow”, transpose the incoming data. This option allows you to import files where the series are contained in rows (one row per series) rather than columns.
The optional variables_description may be formed using the elements:
• “colhead=int”, number of table rows to be treated as column headers.
• “na="arg1"”, text used to represent observations that are missing from the file. The text should be enclosed on double quotes.
• “scan=[int|all]”, number of rows of the table to scan during automatic format detection (“scan=all” scans the entire file).
• “firstobs=int”, first observation to be imported from the table of data (default is 1). This option may be used to start reading rows from partway through the table.
• “lastobs = int”, last observation to be read from the table of data (default is last observation of the file). This option may be used to read only part of the file, which may be useful for testing.
HTML Examples
vec1.import "c:\data.html"
loads into the VEC1 vector object the data located in the HTML file “Data.HTML” located on the C:\ drive
vec1.import(type=html) "http://www.tradingroom.com.au/apps/mkt/forex.ac" colhead=3
loads into a vector object called VEC1 the data with the given URL located on the website site “http://www.tradingroom.com.au”. The column header is set to three rows.
Text and Binary Files
The syntax for reading text or binary files is:
vector_name.import(type=arg) source_description [table_description] [variables_description]
If a table_description is not provided, EViews will attempt to read the file as a free-format text file. The following table_description elements may be used when reading a text or binary file:
• “ftype = [ascii|binary]” specifies whether numbers and dates in the file are stored in a human readable text (ASCII), or machine readable (Binary) form.
• “rectype = [crlf|fixed|streamed]” describes the record structure of the file:
“crlf”, each row in the output table is formed using a fixed number of lines from the file (where lines are separated by carriage return/line feed sequences). This is the default setting.
“fixed”, each row in the output table is formed using a fixed number of characters from the file (specified in “reclen= arg”). This setting is typically used for files that contain no line breaks.
“streamed”, each row in the output table is formed by reading a fixed number of fields, skipping across lines if necessary. This option is typically used for files that contain line breaks, but where the line breaks are not relevant to how rows from the data should be formed.
• “reclines =int”, number of lines to use in forming each row when “rectype=crlf” (default is 1).
• “reclen=int”, number of bytes to use in forming each row when “rectype=fixed”.
• “recfields=int”, number of fields to use in forming each row when “rectype=streamed”.
• “skip=int”, number of lines (if rectype is “crlf”) or bytes (if rectype is not “crlf”) to discard from the top of the file.
• “comment=string“, where string is a double-quoted string, specifies one or more characters to treat as a comment indicator. When a comment indicator is found, everything on the line to the right of where the comment indicator starts is ignored.
• “emptylines=[keep|drop]”, specifies whether empty lines should be ignored (“drop”), or treated as valid lines (“keep”) containing missing values. The default is to ignore empty lines.
• “tabwidth=int”, specifies the number of characters between tab stops when tabs are being replaced by spaces (default=8). Note that tabs are automatically replaced by spaces whenever they are not being treated as a field delimiter.
• “fieldtype=[delim|fixed|streamed|undivided]”, specifies the structure of fields within a record:
“Delim”, fields are separated by one or more delimiter characters
“Fixed”, each field is a fixed number of characters
“Streamed”, fields are read from left to right, with each field starting immediately after the previous field ends.
“Undivided”, read entire record as a single series.
• “quotes=[single|double|both|none]”, specifies the character used for quoting fields, where “single” is the apostrophe, “double” is the double quote character, and “both” means that either single or double quotes are allowed (default is “both”). Characters contained within quotes are never treated as delimiters.
• “singlequote“, same as “quotes = single”.
• “delim=[comma|tab|space|dblspace|white|dblwhite]”, specifies the character(s) to treat as a delimiter. “White” means that either a tab or a space is a valid delimiter. You may also use the abbreviation “d=” in place of “delim=”.
• “custom="arg1"”, specifies custom delimiter characters in the double quoted string. Use the character “t” for tab, “s” for space and “a” for any character.
• “mult=[on|off]”, to treat multiple delimiters as one. Default value is “on” if “delim” is “space”, “dblspace”, “white”, or “dblwhite”, and “off” otherwise.
• “endian = [big|little]”, selects the endianness of numeric fields contained in binary files.
• “string = [nullterm|nullpad|spacepad]”, specifies how strings are stored in binary files. If “nullterm”, strings shorter than the field width are terminated with a single zero character. If “nullpad”, strings shorter than the field width are followed by extra zero characters up to the field width. If “spacepad”, strings shorter than the field width are followed by extra space characters up to the field width.
• “byrow”, transpose the incoming data. This option allows you to import files where the series are contained in rows (one row per series) rather than columns.
• “lastcol”, include implied last column. For lines that end with a delimiter, this option adds an additional column.
When importing a CSV file, lines which have the delimiter as the last character (for example: ‘name,description,date,’), EViews normally determines the line to have 3 columns. With the above option, EViews will determine the line to have 4 columns. Note this is not the same as a line containing ‘name,description,date’. In this case, EViews will always determine the line to have 3 columns regardless if the option is set.
A central component of the table_description element is the format statement. You may specify the data format using the following table descriptors:
• Fortran Format:
fformat=([n1]Type[Width][.Precision], [n2]Type[Width][.Precision], ...)
where Type specifies the underlying data type, and may be one of the following,
I - integer
F - fixed precision
E - scientific
A - alphanumeric
X - skip
and n1, n2, ... are the number of times to read using the descriptor (default=1). More complicated Fortran compatible variations on this format are possible.
• Column Range Format:
rformat="[n1]Type[Width][.Precision], [n2]Type[Width][.Precision], ...)"
where optional type is “$” for string or “#” for number, and n1, n2, n3, n4, etc. are the range of columns containing the data.
• C printf/scanf Format:
cformat="fmt"
where fmt follows standard C language (printf/scanf) format rules.
The optional variables_description may be formed using the elements:
• “colhead=int”, number of table rows to be treated as column headers.
• “types=("arg1","arg2",…)”, user specified data types of the series. If types are provided they will override the types automatically detected by EViews. You may use any of the following format keywords: “a” (character data), “f” (numeric data), “d” (dates), or “w” (EViews automatic detection). This option is rarely used.
• “na="arg1"”, text used to represent observations that are missing from the file. The text should be enclosed on double quotes.
• “scan=[int|all]”, number of rows of the table to scan during automatic format detection (“scan=all” scans the entire file).
• “firstobs=int”, first observation to be imported from the table of data (default is 1). This option may be used to start reading rows from partway through the table.
• “lastobs = int”, last observation to be read from the table of data (default is last observation of the file). This option may be used to read only part of the file, which may be useful for testing.
Text and Binary File Examples (.txt, .csv, etc.)
vec2.import c:\data.csv skip=5
reads “Data.CSV” into VEC2, skipping the first 5 rows.
vec01.import(type=text) c:\date.txt delim=comma
loads the comma delimited data DATE.TXT into the VEC01 vector object.
Cross-references
Display or change the label view of the vector, including the last modified date and display name (if any).
Used as a procedure, label changes the fields in the vector label.
Syntax
vector_name.label
vector_name.label(options) [text]
Options
The first version of the command displays the label view of the vector. The second version may be used to modify the label. Specify one of the following options along with optional text. If there is no text provided, the specified field will be cleared.
c | Clears all text fields in the label. |
d | Sets the description field to text. |
s | Sets the source field to text. |
u | Sets the units field to text. |
r | Appends text to the remarks field as an additional line. |
p | Print the label view. |
Examples
The following lines replace the remarks field of LWAGE with “Data from CPS 1988 March File”:
lwage.label(r)
lwage.label(r) Data from CPS 1988 March File
To append additional remarks to LWAGE, and then to print the label view:
lwage.label(r) Log of hourly wage
lwage.label(p)
To clear and then set the units field, use:
lwage.label(u) Millions of bushels
Cross-references
See
“Labeling Objects” for a discussion of labels. See also
Vector::displayname.
Push updates to OLE linked objects in open applications.
Syntax
vector_name.olepush
Cross-references
See
“Object Linking and Embedding (OLE)” for a discussion of using OLE with EViews.
Import data from a foreign disk file into a vector.
(This is a deprecated method of importing into a vector. See
Vector::import for the supported method.)
May be used to import data into an existing workfile from a text, Excel, or Lotus file on disk.
Syntax
vector_name.read(options) [path\]file_name
You must supply the name of the source file. If you do not include the optional path specification, EViews will look for the file in the default directory. Path specifications may point to local or network drives. If the path specification contains a space, you may enclose the entire expression in double quotation marks.
Options
prompt | Force the dialog to appear from within a program. |
File type options
:
t=dat, txt | ASCII (plain text) files. |
t=wk1, wk3 | Lotus spreadsheet files. |
t=xls | Excel spreadsheet files. |
If you do not specify the “t” option, EViews uses the file name extension to determine the file type. If you specify the “t” option, the file name extension will not be used to determine the file type.
Options for ASCII text files
na=text | Specify text for NAs. Default is “NA”. |
d=t | Treat tab as delimiter (note: you may specify multiple delimiter options). The default is “d=c” only. |
d=c | Treat comma as delimiter. |
d=s | Treat space as delimiter. |
d=a | Treat alpha numeric characters as delimiter. |
custom = symbol | Specify symbol/character to treat as delimiter. |
mult | Treat multiple delimiters as one. |
rect (default) / norect | [Treat / Do not treat] file layout as rectangular. |
skipcol = integer | Number of columns to skip. Must be used with the “rect” option. |
skiprow = integer | Number of rows to skip. Must be used with the “rect” option. |
comment= symbol | Specify character/symbol to treat as comment sign. Everything to the right of the comment sign is ignored. Must be used with the “rect” option. |
singlequote | Strings are in single quotes, not double quotes. |
dropstrings | Do not treat strings as NA; simply drop them. |
negparen | Treat numbers in parentheses as negative numbers. |
allowcomma | Allow commas in numbers (note that using commas as a delimiter takes precedence over this option). |
Options for spreadsheet (Lotus, Excel) files
letter_number (default=“b2”) | Coordinate of the upper-left cell containing data. |
s=sheet_name | Sheet name for Excel 5–8 Workbooks. |
Examples
v1.read(t=dat,na=.) a:\mydat.raw
reads data into vector V1 from an ASCII file MYDAT.RAW in the A: drive. The missing value NA is coded as a “.” (dot or period).
v1.read(s=sheet2) "\\network\dr 1\cps91.xls"
reads the Excel file CPS91 into vector V1 from the network drive specified in the path.
Cross-references
See
“Importing Data” for a discussion and examples of importing data from external files.
Resample from observations in a vector.
Syntax
vector_name.resample(options) [output_spec]
You should follow the resample keyword and options and an output_spec containing a list of names or a wildcard expression identifying the series to hold the output. If a list is used to identify the targets, the number of target series must match the number of names implied by the keyword.
Options
permute | Draw from rows without replacement. Default is to draw with replacement. |
weight= vector_name | Name of vector to be used for weighted sampling, containing values proportional to the desired row probabilities (importance sampling). The weight vector must have the same number of rows as the source, with non-missing, non-negative values. The weight values need not add up to 1, as EViews will normalize the weights. If no weights are specified, rows will be drawn with equal probability weights. |
block=integer (default = 1) | Block length for each draw. Must be a positive integer. The default block length is 1. |
withna (default) | [Draw / Do not draw] from all rows in the current sample, including those with NAs. |
dropna | Do not draw from rows that contain missing values in the current workfile sample. |
fixna | Excludes NAs from draws but copies rows containing missing values to the output series. |
prompt | Force the dialog to appear from within a program. |
• Block bootstrap (block length larger than 1) requires a continuous output sample. Therefore a block length larger than 1 cannot be used together with the “fixna” option, and the “outsmpl” should not contain any gaps.
• The “fixna” option will have an effect only if there are missing values in the overlapping sample of the input sample (current workfile sample) and the output sample specified by “outsmpl”.
• If you specify “fixna”, we first copy any missing values in the overlapping sample to the output series. Then the input sample is adjusted to drop rows containing missing values and the output sample is adjusted so as not to overwrite the copied values.
• If you choose “dropna” and the block length is larger than 1, the input sample may shrink in order to ensure that there are no missing values in any of the drawn blocks.
• If you choose “permute”, the block option will be reset to 1, the “dropna” and “fixna” options will be ignored (reset to the default “withna” option), and the “weight” option will be ignored (reset to default equal weights).
Examples
vec1.resample vec1_b
creates a new vector VEC1 by drawing with replacement from the rows of VEC1 in the current workfile sample. If VEC1_B already exists in the workfile and is a vector object, it will be overwritten. If VEC1_B exists and is not a vector, EViews will error.
vec1.resample(weight=wt, suffix=_2) vec1_c
The rows in the source vector will be drawn from with probabilities proportional to the corresponding values in the WT vector. WT must have the same number of rows as VEC1 and must have non-missing, non-negative values.
Cross-references
See
“Resample” for a discussion of the resampling procedure. For additional discussion of wildcards, see
Appendix A. “Wildcards”.
See also
@resample and
@permute for sampling from matrices.
Resize the vector object.
Syntax
vector_name.resize rows
Examples
vec1.resize 20
resizes the vector VEC1 to 20 rows, retaining the contents of any existing elements and initializing new elements to 0.
Set the object attribute.
Syntax
vector_name.setattr(attr) attr_value
Sets the attribute attr to attr_value. Note that quoting the arguments may be required. Once added to an object, the attribute may be extracted using the @attr data member.
Examples
a.setattr(revised) never
String s = a.@attr("revised")
sets the “revised” attribute in the object A to the string “never”, and extracts the attribute into the string object S.
Cross-references
Set the column label in a vector object.
Syntax
vector_name.setcollabels label1
Follow the setcollabels command with the column label. Note that the column label should not contain spaces unless it is enclosed in quotes.
Examples
vec1.setcollabels MyResults
sets the column label to “MyResults”.
Cross-references
Set the display format for cells in a vector spreadsheet view.
Syntax
vector_name.setformat format_arg
where format_arg is a set of arguments used to specify format settings. If necessary, you should enclose the format_arg in double quotes.
For vectors, setformat operates on all of the cells in the vector.
You should use one of the following format specifications:
g[.precision] | significant digits |
f[.precision] | fixed decimal places |
c[.precision] | fixed characters |
e[.precision] | scientific/float |
p[.precision] | percentage |
r[.precision] | fraction |
To specify a format that groups digits into thousands using a comma separator, place a “t” after the format character. For example, to obtain a fixed number of decimal places with commas used to separate thousands, use “ft[.precision]”.
To use the period character to separate thousands and commas to denote decimal places, use “..” (two periods) when specifying the precision. For example, to obtain a fixed number of characters with a period used to separate thousands, use “ct[..precision]”.
If you wish to display negative numbers surrounded by parentheses (i.e., display the number -37.2 as “(37.2)”), you should enclose the format string in “()” (e.g., “f(.8)”).
Examples
To set the format for all cells in the vector to fixed 5-digit precision, simply provide the format specification:
v1.setformat f.5
Other format specifications include:
v1.setformat f(.7)
v1.setformat e.5
Cross-references
See
Vector::setwidth,
Vector::setindent and
Vector::setjust for details on setting spreadsheet widths, indentation and justification.
Copy the contents of the vector object into the workfile C coefficient vector.
Syntax
vector_name.setglobalc
This function only applies to vectors, rowvectors and coef objects. The contents of the vector will be copied into the first N elements of the workfile C coefficient vector, where N is the length of the vector object. This may be useful for re-specifying starting values for estimation.
Examples
vec1.setglobalc
Copies the contents of VEC1 into the workfile C vector.
Cross-references
Set the display indentation for cells in vector spreadsheet views.
Syntax
view_name.setindent indent_arg
where indent_arg is an indent value specified in 1/5 of a width unit. The width unit is computed from representative characters in the default font for the current spreadsheet (the EViews spreadsheet default font at the time the spreadsheet was created), and corresponds roughly to a single character. Indentation is only relevant for non-center justified cells.
The default indentation setttings are taken from the Global Defaults for spreadsheet views (
“Spreadsheet Data Display”) at the time the spreadsheet was created.
Examples
v1.setindent 2
sets the indentation for the vector spreadsheet view to 2.
Cross-references
See
Vector::setwidth and
Vector::setjust for details on setting spreadsheet widths and justification.
Set the horizontal justification for all cells in the spreadsheet view of the vector object.
Syntax
vector_name.setjust format_arg
where
format_arg may be set to left, center, right, or auto (strings are left-justified and numbers are right-justified). Default display settings can be set in General Options; see
“Spreadsheet Data Display”.
Examples
vec1.setjust left
left-justifies the cells in the spreadsheet view of the vector VEC1.
Cross-references
See
Vector::setwidth and
Vector::setindent for details on setting spreadsheet widths and indentation.
Set the row labels in a vector object.
Syntax
vector_name.setrowlabels label1 label2 label3....
Follow the setrowlabels command with a space delimited list of row labels. Note that each row label should not contain spaces unless it is enclosed in quotes. If you provide fewer labels than there are rows, EViews will keep the corresponding default row names (“R11”, “R12”, etc...).
Examples
vec1.setrowlabels USA UK FRANCE
sets the row label for the first row in vector VEC1 to USA, the second to UK, and the third to FRANCE.
Cross-references
Set the column width in a vector spreadsheet view.
Syntax
vector_name.setwidth width_arg
where width_arg specifies the width unit value. The width unit is computed from representative characters in the default font for the current spreadsheet (the EViews spreadsheet default font at the time the spreadsheet was created), and corresponds roughly to a single character. width_arg values may be non-integer values with resolution up to 1/10 of a width unit.
Examples
v1.setwidth 12
sets the width of the vector to 12 width units.
Cross-references
See
Vector::setindent and
Vector::setjust for details on setting spreadsheet indentation and justification.
Spreadsheet view of vector object.
Syntax
vector_name.sheet(options)
Options
p | Print the spreadsheet view. |
Examples
v1.sheet(p)
displays and prints the spreadsheet view of vector V1.
Displays the custom row and column labels of a vector spreadsheet.
Syntax
vector_name.showlabels mode
where mode is either 0 or 1 where 0 displays the default row and column labels and 1 displays the custom row and column labels (if present).
Examples
v1.showlabels 1
displays the custom row and column labels for the V1 spreadsheet. If custom labels have not been set the default labels will be displayed.
v1.showlabels 0
displays the default row and column labels for the V1 spreadsheet.
Cross-references
Basic statistics by classification.
The statby view displays descriptive statistics for the elements of a vector classified into categories by a vector or columns of a matrix.
Syntax
vector_name.statby(options) classifier
You should follow the vector name with a period, the statby keyword, and a name (or a list of names) for the vector or matrix containing row values by which to classify.
The options control which statistics to display and in what form. By default, statby displays the means, standard deviations, and counts.
Options
Options to control statistics to be displayed
sum | Display sums. |
med | Display medians. |
max | Display maxima. |
min | Display minima. |
quant=arg (default=.5) | Display quantile with value given by the argument. |
q=arg (default=“r”) | Compute quantiles using the specified definition: “b” (Blom), “r” (Rankit-Cleveland), “o” (Ordinary), “t” (Tukey), “v” (van der Waerden), “g” (Gumbel). |
skew | Display skewness. |
kurt | Display kurtosis. |
na | Display counts of NAs. |
nomean | Do not display means. |
nostd | Do not display standard deviations. |
nocount | Do not display counts. |
Options to control layout
l | Display in list mode (for more than one classifier). |
nor | Do not display row margin statistics. |
noc | Do not display column margin statistics. |
nom | Do not display table margin statistics (unconditional tables); for more than two classifier series. |
nos | Do not display sub-margin totals in list mode; only used with “l” option and more than two classifier series. |
sp | Display sparse labels; only with list mode option, “l”. |
Options to control binning
dropna (default), keepna | [Drop/Keep] NA as a category. |
v=integer (default=1000) | Bin categories if classification series take on more than the specified number of distinct values. |
nov | Do not bin based on the number of values of the classification series. |
a=number (default=2) | Bin categories if average cell count is less than the specified number. |
noa | Do not bin based on the average cell count. |
b=integer (default=5) | Set maximum number of binned categories. |
nolimit | Remove prompt warning for continuing when the total number of cells is very large. |
Other options
prompt | Force the dialog to appear from within a program. |
p | Print the descriptive statistics table. |
Examples
vec1.statby(max, min) vec2
displays the mean, standard deviation, maximum, and minimum of the vector VEC1 by (possibly binned) values of the matching length vector VEC2.
Cross-references
See
“By-Group Statistics” for a list of functions to compute by-group statistics. See also
“Stats by Classification” for discussion.
Descriptive statistics.
Computes and displays a table of means, medians, maximum and minimum values, standard deviations, and other descriptive statistics of the vector.
Syntax
vector_name.stats(options)
Options
Examples
vec1.stats
displays the descriptive statistics view of the elements of the vector VEC1.
Cross-references
See
“Descriptive Statistics & Tests” for a discussion of the descriptive statistics views of series.
Test equality of the mean, median, or variance of the data in a vector across categories defined by the row values of a vector or matrix.
Syntax
vector_name.testby(options) arg1 [arg2 arg2 …]
Follow the testby keyword by a list of the names of the vector or matrix whose rows contain the classifier values.
By default, testby will test for equality of means, but you may specify instead tests of medians or variances as an option, choose whether to use balanced or unbalanced samples, and control binning.
Options
mean (default) | Test equality of means. |
med | Test equality of medians. |
var | Test equality of variances. |
dropna (default), keepna | [Drop /Keep] NAs as a classification category. |
v=integer (default=1000) | Bin categories if classification series take more than the specified number of distinct values. |
nov | Do not bin based on the number of values of the classification series. |
a=number (default=2) | Bin categories if average cell count is less than the specified number. |
noa | Do not bin on the basis of average cell count. |
b=integer (default=5) | Set maximum number of binned categories. |
nolimit | Remove prompt warning for continuing when the total number of cells is very large. |
prompt | Force the dialog to appear from within a program. |
p | Print the test results. |
Examples
vec1.testby(a=10) vec2
tests equality of means of VEC1 across groups classified by values of the matching length vector VEC2, with binning of the average cell count is less than 10.
vec1.testby(med, nov) vec2
tests equality of medians of VEC1 across groups classified by VEC2, with no automatic binning on the basis of the number of unique VEC2 values.
Cross-references
See
“Equality Tests by Classification” for a discussion of equality tests.
Test simple hypotheses of whether the mean, median, or variance of the elements of a vector are equal to specific values.
Syntax
vector_name.teststat(options)
Specify the type of test and the value under the null hypothesis as an option. You must specify at least one hypothesis.
For tests of means, you may either estimate the variance or specify the variance as an option.
Options
mean=number | Test the null hypothesis that the mean equals the specified number. |
med=number | Test the null hypothesis that the median equals the specified number. |
var=number | Test the null hypothesis that the variance equals the specified number. The number must be positive. |
std=number | Test equality of mean conditional on the specified standard deviation. The standard deviation must be positive. |
prompt | Force the dialog to appear from within a program. |
p | Print the test results. |
Examples
vec1.teststat(mean=7)
tests the null hypothesis that the mean of VEC1 is equal to 7, using an estimated standard deviation.
vec1.teststat(mean=7, std=2)
tests the null that the mean is 7, using an estimated standard deviation, and also assuming that the standard deviation is known to be 2.
vec1.teststat(var=4)
tests the null hypothesis that the variance of VEC1 is equal to 4.
Cross-references
See
“Descriptive Statistics & Tests” for a discussion of simple hypothesis tests.
Declare a vector object.
The vector command declares and optionally initializes a (column) vector object.
Syntax
vector(size) vector_name [=assignment]
The keyword vector should be followed by the name you wish to give the vector. You may also provide an optional argument specifying the size of the vector. If you do not provide a size, EViews will create a single element vector. Once declared, vectors may be resized by repeating the command with a new size.
You may combine vector declaration and assignment. If there is no assignment statement, the vector will initially be filled with zeros.
Examples
vector vec1
vector(10) col3 = 3
rowvector(10) row3 = 3
vector vec3 = row3
VEC1 is declared as a single element vector initialized to 0. COL3 is a 10 element column vector containing the value 3. ROW3 is declared as a row vector of size 10 containing the value 3. Although declared as a column vector, VEC3 is reassigned as a row vector of size 10 with all elements equal to 3.
Cross-references
See
“Matrix Language” for a discussion of matrices and vectors in EViews.
Write EViews data to a text (ASCII), Excel, or Lotus file on disk.
Creates a foreign format disk file containing data in a vector object. May be used to export EViews data to another program.
This routine should realistically only be used in the oft-hand chance that you wish to write into a Lotus file. Improved Excel, text, and other format writing is available in
Vector::export.
Syntax
vector_name.write(options) [path\filename]
Follow the name of the vector object by a period, the keyword, and the name for the output file. The optional path name may be on the local machine, or may point to a network drive. If the path name contains spaces, enclose the entire expression in double quotation marks. The entire vector will be exported.
Note that EViews cannot, at present, write into an existing file. The file that you select will, if it exists, be replaced.
Options
prompt | Force the dialog to appear from within a program. |
File type
t=dat, txt | ASCII (plain text) files. |
t=wk1, wk3 | Lotus spreadsheet files. |
t=xls | Excel spreadsheet files. |
If you omit the “t=” option, EViews will determine the type based on the file extension. Unrecognized extensions will be treated as ASCII files. For Lotus and Excel spreadsheet files specified without the “t=” option, EViews will automatically append the appropriate extension if it is not otherwise specified.
ASCII text files
na=string | Specify text string for NAs. Default is “NA”. |
d=arg | Specify delimiter (default is tab): “s” (space), “c” (comma). |
Spreadsheet (Lotus, Excel) files
letter_number | Coordinate of the upper-left cell containing data. |
Examples
v1.write(t=txt,na=.) a:\dat1.csv
Writes the vector V1 into an ASCII file named DAT1.CSV on the A: drive. NAs are coded as “.” (dot).
v1.write(t=txt,na=.) dat1.csv
writes the same file in the default directory.
v1.write(t=xls) "\\network\drive a\results"
saves the contents of V1 in an Excel file “Results.xls” in the specified directory.
Cross-references